As I’ve been working in the project that try to determine the optimum nitrogen rate for double cropping winter cereal in New York State, one basic but important part in it is to fit the yield nitrogen fertilizer response data from individual experiment site into different statistical models.
- The following is the general regression model:
![]()
where Yi refers to the yield response variables, β0 refers to the intercept, Xi refers to the nitrogen fertilizer rate, βi refers to the coefficient of the nitrogen fertilizer rate, and εi is the random error.
Then the following is the five specific models based on the general regression model, which is quadratic model, exponential model, square root model, quadratic plateau model and linear plateau model.
- Quadratic model:
![]()
where Yi refers to the yield response variables, β0 refers to the intercept, Xi refers to the nitrogen fertilizer rate, β1 refers to the linear coefficient, β2 refers to the quadratic coefficient, and εi is the random error.
- Exponential model:
![]()
where Yi refers to the yield response variables, β0 refers to the maximum yield when the nitrogen rate is not limited, β1 refers to the increase of yield per unit of nitrogen rate, β2 refers to the nitrogen value in soil with the same unit as the nitrogen fertilizer rate, and εi is the random error.
- Square root model:
![]()
where Yi refers to the yield response variables, β0 refers to the intercept, Xi refers to the nitrogen fertilizer rate, β1 refers to the linear coefficient, β2 refers to the square root coefficient, and εi is the random error.
- Quadratic plateau model:
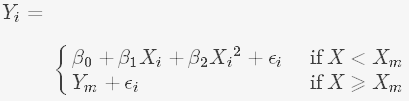

where Xm is the critical point after which the increase of nitrogen fertilizer can no longer increase yield, and Ym is the maximum yield. The other coefficients have the same meaning as those in quadratic model. The plateau occurs when the quadratic curve comes to its maximum point.
- Linear plateau model:
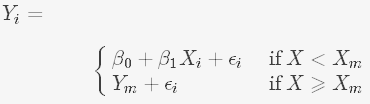
![]()
where Yi refers to the yield response variables, β0 refers to the intercept, Xi refers to the nitrogen fertilizer rate, β1 refers to the linear coefficient, and εi is the random error. Xm is the critical point after which the increase of nitrogen fertilizer can no longer increase yield, and Ym is the maximum yield.
I use R to fit the data with these models. Among them, we can easily use linear regression function when dealing with quadratic and square root model. For example:
fit_quadratic<-lm(Yield~I(NTrmt)^2+NTrmt, data= site_1_2013)
However, we need to use nonlinear regression function to fit with exponential, quadratic plateau and linear plateau model. An easy and understandable way to do it is followed:
linear.plateau=function(A,B,C,x){
ifelse(x<C,A+B*x,A+B*C)
}
fit_linear.plateau<-nls(Yield~linear.plateau(A,B,C,x=NTrmt),
data = site_1_2013,start=list(A=1.33,B=0.017,C=60))
This means that we can create a function of the formula of that model first, and then use this newly created function in the nonlinear regression function.
However, One of the biggest challenges here is to determine the starting value, as it is shown in the code:
start=list(A=1.33,B=0.017,C=60)
The starting value can be regarded as a guessing value of each coefficient. The reason we need to input such a starting value is that only when the starting value is close to the “real value” can the computer find out the “real value” within certain number iterations.
The proper starting value can usually be estimated following these steps:
- Plot the data point.
- Understand the meaning of each coefficient, and obtain the possible value of some coefficients based on the plot. For instance, in linear plateau model, β0 is the intercept, so we can estimate β0 by using the intercept of Y-axis in the plot.
- Select some representative points in the plot, and use the data of these plots in the corresponding formula to calculate possible coefficients. For example, in linear plateau model, we choose two representative points (0,b) and (c,d), where (0,b) is the a point on the Y axis, and (c,d) is the point of highest yield, so that Xm=c, Ym=d, β0=b, β1=(d-b)/c.