Using MapReduce to Compute PageRank
MapReduce is an algorithm/data processing model that is introduced by Google research in the early 2000s. It is extremely useful for parallel processing and distributed computing of big sets of data. It basically contains three phases: Mapping, Shuffling and Reducing
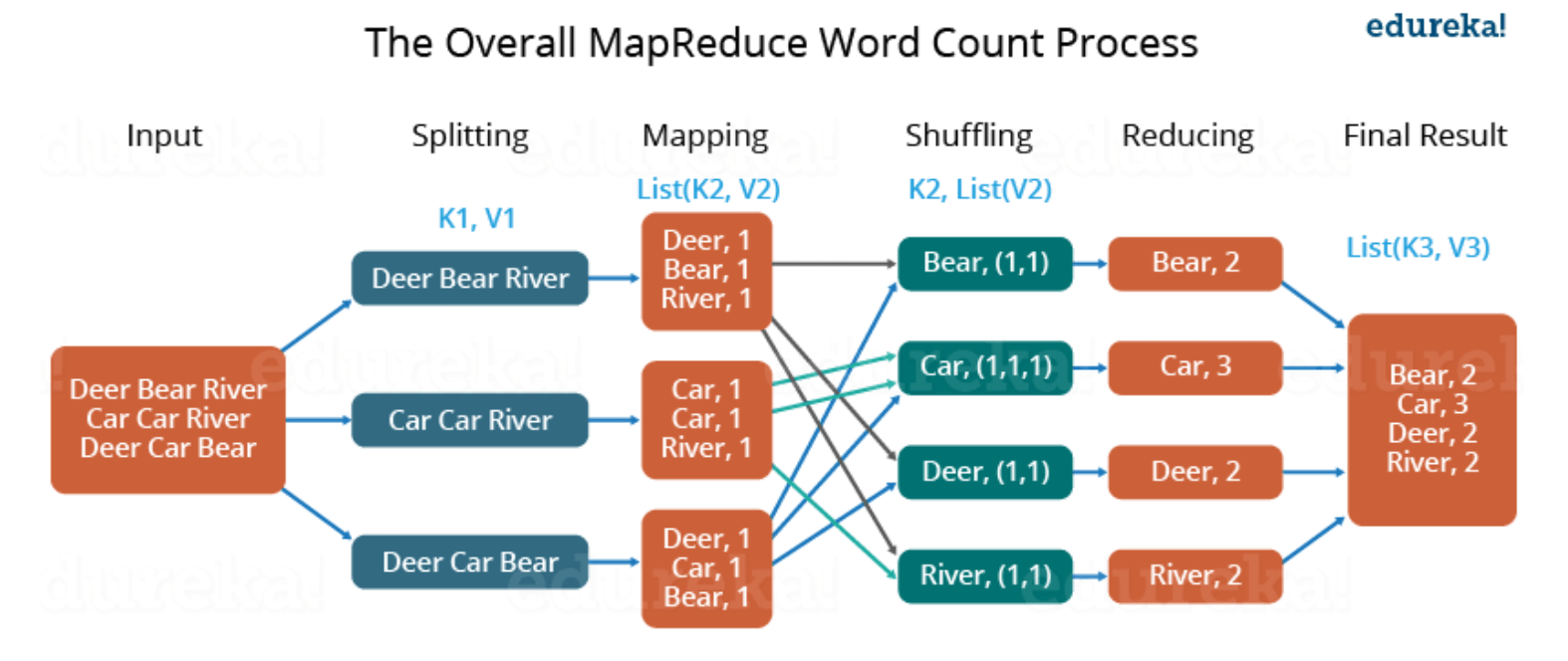
- Mapping phase takes some high volume input (usually a GFS/HDFS file), and breaks them into key-value pairs.
- Shuffling phase takes the outputs from Mapping phase and sorts them by their keys. And all inputs with the same key will be allocated to the same place.
- Reducing phase takes the outputs from Shuffling phase and do some computations (programmable based on one’s need) on those data. It will finally store the results.
MapReduce allows distributed computing, meaning a program can be computed on multiple computers to improve efficiency. This would be really useful because it means, for example, we can process huge volumes of webpage data for a search engine – i.e. Webpage data collected by Google’s crawlers can be fed into the MapReduce model to calculate the resulting page ranks under a Pagerank algorithm, and the result will be stored in a BigTable.
However, MapReduce also have its weakness – for example, the original model cannot handle stream data (real-time data) – which basically means that the model can only process a batch of data after the previous batch has finished its calculation. In the search engine scenario, this means that we cannot crawling the webpages and doing MapReduce calculation to store the results at the same time. On the other hand, the processing speed of MapReduce is not that fast due to it requires relatively long time to perform mapping and reducing. This results in very high latency in real-time data processing/searching scenario when we do not have any previously stored result data.
References:
Article link: http://michaelnielsen.org/blog/using-mapreduce-to-compute-pagerank/
Paper link: MapReduce: Simplified Data Processing on Large Clusters / Jeffrey Dean and Sanjay Ghemawat