Using Bayes Theorem to Classify Incoming Emails
It is often important to reinforce topics learned in the classroom with real world examples. For instance, when taught purely based on theory, the real world importance of Bayes’ Theorem can easily be lost. The ability to calculate conditional probability based on other known probabilities is crucial to several pieces of technology we interact with in the real world. One such example is the software that allows our email accounts to filter out spam emails. In machine learning, a naïve bayes classifier is a relatively robust algorithm that can predict the classification of “feature vectors” (numerical representations of everyday objects such as text documents or images) based on a large set of training data.
An important and easy-to-understand application of a naïve bayes classifier is in the classification of emails (specifically whether an email should be considered spam or not). This is done in several steps. The first is to acquire a large collection of emails whos classification is already known (the training data). This is the information that will be used to determine the likelihood of a new email being spam. Once these emails have been compiled they can be converted into feature vectors by simply counting the number occurrences of each word and placing these values in a vector.
The trick to a naïve bayes classifier is to estimate the probability of a classification (spam or not spam) given the feature vector as so:
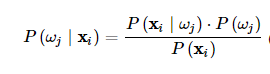
Where xi represents the feature vector and wj represents the classification. The probability of the classification is simply the number of elements in the classification (the number of spam emails) divided by the total number of samples. Because the algorithm works my looking for the maximum probability and the denominator will be the same regardless of class, the formula can be simplified to include only the numerator. The probability of a feature vector given the classification is derived by looking at the original dataset, and with all this information we are able to accurately assign labels to incoming emails.
This clever application of Bayes rules gives us the power to teach an algorithm to classify incoming emails based on content by simply looking at a large enough sample of previously classified information. By using only Bayes theorem the system is fairly straightforward and easy to understand at a conceptual level.
Source:
http://sebastianraschka.com/Articles/2014_naive_bayes_1.html
http://blog.datumbox.cofjklsjm/machine-learning-tutorial-the-naive-bayes-text-classifier/