Google Can’t Search the Deep Web, So How Do Deep Web Search Engines Work?
Link: https://blog.torproject.org/tor-heart-ahmia-project
Introduction:
If search engines like Google, Yahoo, and Bing are unable to index the deep web, then how do deep web search engines work? We’ll try to answer this question by first what I mean by “deep web”, then explaining why Google can’t crawl the deep web, and finally looking at how some popular search engines like Ahmia and the Uncensored Hidden Wiki “search” the deep web.
Deep Web:
According to Google’s online dictionary, the deep web is “the part of the World Wide Web that is not discoverable by means of standard search engines, including password-protected or dynamic pages and encrypted networks”. It is estimated that search engines like Google index only 4% of the entire world wide web, meaning that the deep web is nearly 25 times larger than the internet you and I have used our whole lives. Note: the deep web shouldn’t be confused with the “dark web”, which pertains strictly to pages containing illegal content such as child pornography, terrorist forums, and illegal auctions/transactions.
Google Can’t Crawl the Deep Web:
Google’s search engine functions by using “crawlers”. (1) These crawlers start from a list of known web addresses, visit those pages, then follow the links contained on those pages, and continue following links found on the new pages, collecting information about each page as they go. Now, consider a single page in the deep web. Google’s search engine could be unable to find this page because of several reasons. For one, Google’s crawlers might never come across this page simply because no other previously crawled page links to it. Additionally, this page might require some sort of authentication such as filling out a search form and clicking submit, or having a certain certificate. Also, if a page contains illegal content, Google will likely not want that content appearing in search results, so they won’t index it. Finally, if the creator of a page doesn’t want it to be indexed by popular search engines, they can include a suitable robots.txt file, which tells the crawlers not to index the page. If the crawlers index the page anyways, then legal action can be taken against the creator of the crawlers, and the search engine can end up on a bot reporting site like http://www.botreports.com/badbots/ (2).
“Deep Web Search Engines”:
There are many “deep web search engines”, but I’ll focus on two: Ahmia, and the Uncensored Hidden Wiki.
Ahmia was developed by Juha Nurmi as part of the Tor Project, and it is one of the closest things to a deep web search engine (3). Ahmia essentially collects .onion URLs from the Tor network, then feeds these pages to their index provided that they don’t contain a robots.txt file saying not to index them (4). Additionally, Ahmia allows onion service operators to register their own URLs, enabling them to be found. Through continuously collecting .onion URLs, Ahmia has created one of the largest indexes of the deep web. That being said, it still comes nowhere near to scratching the surface of the whole deep web, but it indexes a good portion of the content that most people would want to look for.
The Uncensored Hidden Wiki operates a little differently. Anyone can register on the Uncensored Hidden Wiki, and after that, anyone can edit the links contained in the database. The search engine operates by searching the provided descriptions of the pages at these links. This certainly has its pros and cons. On the bright side, crowd-sourcing the links is one of the best ways to collect a large number of useful URLs, and keep them up to date (especially since .onion domain names change extremely often). On the other hand, anyone can change the links to wherever they want, or alter the descriptions of the links. The negatives of this can be mitigated by site admins to ensure that the links are usually accurate, but there are no guarantees when using the links on this page. Additionally, the Uncensored Hidden Wiki has its name for a reason, as the content of that page is certainly uncensored.
Conclusion:
While the “deep web search engines” mentioned above are capable of indexing a good part of the deep web, the vast majority of it remains unindexed, and no search engine is capable of finding everything contained in it. The best deep web search engines function in various ways, whether it be crowd-sourcing URLs and page descriptions or continuously collecting them, but they certainly do not function in similar ways to traditional search engines such as Google. If you want to learn more about the deep web, you can find plenty of information about the deep web using Google (how ironic). If you want to search the deep web yourself, here’s my advice: don’t. Especially if you’ve never heard of terms like .onion, Tor gateways, proxies, botnets, Trojans, etc. If you’re anything like me then you have no business searching the deep web, as it can be dangerous if you’re not extremely careful protecting your identity, even when using the search engines mentioned above in conjunction with the Tor browser. The deep web also has very little that you or I would find interesting, and plenty of things that neither you nor I want to see.
Sources:
- https://www.google.com/search/howsearchworks/crawling-indexing/
- http://www.botreports.com/badbots/
- https://blog.torproject.org/tor-heart-ahmia-project
- https://ahmia.fi/documentation/indexing/
‘Click Farms’ And The Value Of Online Advertisements
Right now, somewhere in the Philippines, offices filled with virtual impostors are being paid to assume the identities of thousands of people who do not actually exist. The purpose?—to take advantage of the poorly regulated advertising markets that exist through social media websites and search engines like Facebook, Twitter, and Google. Employees spend their workdays crafting hundreds of realistic profiles to the specific orders of middlemen known as “click farms” who in turn use the accounts to provide thousands of likes, followers, or clicks on advertisements. The article points to evidence which estimates “the market for fake Twitter followers was worth between $40 million and $360 million in 2013, and that the market for Facebook spam was worth $87 million to $390 million” which corresponds perfectly with the estimation that an astounding “7 percent of Facebook’s 1.4 billion accounts and 8.5 percent of Twitter’s 230 million accounts were fake or duplicate.” Of course, it is in the best interest of these social networks to downplay the significance of these fake accounts, as the overwhelming majority of their revenue comes from on-site advertisements. If a company is unknowingly marketing to non-existent people, how can they possibly determine a value for the traffic on their ads?
The very concept of a ‘click farm’ undermines the purpose and principle of matching markets, and concepts like the Vickrey-Clarke-Groves mechanism, and second price auctions, as they all rely on a company determining true values for an advertising slot. Derek Muller, a podcaster who paid Facebook to advertise his product, found only a 1% engagement from the over 80,000 likes he gained through his ads. An analysis of the clicks showed a majority came from individuals in “Egypt, India, the Philippines, (and) Pakistan” where click farms are most likely to be found. While the obvious choice would be to limit your demographic to a country like the U.S, there is nothing preventing a U.S based click farm from skewing the data collected from your advertisements. While it may have previously been obvious for a business to determine how much ‘like’ or a ‘click’ is worth to them, the increasing uncertainty of whether or not these clicks come from actual people means that formulating a value is an increasingly precarious venture. But major companies do not seem to have caught onto this trend yet, Facebook alone has seen an average 9% increase in ad prices per year and an astounding 220% in 2016 alone.If Companies value the quantity of likes on their page rather than the quality of likes, perhaps for the appearance of internet influence, then ‘click farms’ do not pose a problem. But for companies that are concerned with the quality and value of these exchanges, they must not rely on clicks or likes, but instead rely on verifiable data that determines how users engage with their content.
Main Article: http://theweek.com/articles/560046/inside-counterfeit-facebook-farm
Citation from: https://www.washingtonpost.com/news/the-switch/wp/2014/02/10/this-blogger-paid-facebook-to-promote-his-page-he-got-80000-bogus-likes-instead/?utm_term=.ff1dad144990
AI in Google Search
As overseer of Google’s search engine, Amit Singhal, announced his retirement, the overseer of Google’s artificial intelligence, John Giannandrea, stepped up to fill Singhal’s place. Google’s approach to artificial intelligence which involves deep neural networks approximating to the neurons in a human brain is known as deep learning. Deep learning analyzes a lot of data, creating neural nets to learn tasks like recognizing photos, spoken words, and now search queries. Google’s deep learning system, known as RankBrain, interprets human language and query and learns what people prefer whereas the hundreds of other methods for returning a search result use inputted data and tons of experiments. This grows this “gut feeling” and “guessability” of people. Computers generally have trouble with colloquial language, but RankBrain will take in this colloquial language, as humans do, and guess at the meaning based on some past experience and the large net of data to which it has access.
In class, we talked about coming up with the query with the “best” answers. This involved taking weighted votes via in-links and constantly updating the authority based on the hub scores and thereby updating the quality of the list. Understandably, Google already seems to have that without any form of artificial intelligence taking care of this. However, RankBrain seems to take this searching a step further by understanding human language on a deeper more “human” level on top of constantly improving its quality of search queries. From my limited understanding of artificial intelligence and deep learning, RankBrain now has the potential to make the search not only more effective and efficient but more informed to make future decisions and predictions.
Links: https://www.wired.com/2016/02/ai-is-changing-the-technology-behind-google-searches/
https://www.bloomberg.com/news/articles/2015-10-26/google-turning-its-lucrative-web-search-over-to-ai-machines
Good News – No PageRank Toolbar on Google
As what we learned, PageRank is one of the methods Google uses to determine a page’s relevance or importance. It is only one part of the story when it comes to the Google listing, but the other aspects are discussed elsewhere (and are ever changing) and PageRank is interesting enough to deserve a paper of its own. Before last year, PageRank is also displayed on the toolbar of your browser if you’ve installed the Google toolbar.
On 2016, google decided to remove PageRank scores form public view. For all the users, this is such a good news that you do not have to receiving crappy emails, or garbage comments with link drops. When Google first stared, PageRank was something it talked about as part of its research papers, press releases and technology pages to promote itself as a smarter search engine than well-established and bigger rivals at the time — players like Yahoo or AltaVista. Google released the first version of the toolbar to make it easy to search Google directly from within IE. It also gave those who enabled the PageRank meter to see the PageRank score of any page they were viewing. However, this also give “sellers” chanced to review the “buyers”, and fake the PageRank to increase their profit. If they want better PageRank, they want links, and so the link-selling economy emerged. Networks developed so that people could buy links and improve their PageRank scores, in turn potentially improving their ability to rank on Google for different terms. All these demonstrate that how terrible Google make PageRank visible to the Public. It’s really wised that it has been removed.
Reference:
https://www.searchenginejournal.com/google-pagerank-official-shuts-doors-public/161874/
Prevalence of The Winner’s Curse in Initial Public Offerings
When a company first goes public, investors must decide whether or not they want to buy shares at the listed initial price. Since investors intend to resell shares after a holding period, it is important for them to know how other investors value them and how much they can eventually resell them for. Different investors with varying amounts of information about a company will arrive at different future values for a share of its stock.
Immediately after shares of a company begin trading publicly, investors who believe that the true value of a share is higher than its current price will buy some. Increasingly optimistic investors – who believe that the share’s true value exceeds the market’s price – will continue buying shares, which continues to increase its price. Eventually, the share reaches a certain price, specifically, the price that the most optimistic bidder is willing to pay, and stops climbing higher. This typically happens within the first few days of trading.
This scenario can be viewed as a type of auction in which bidders intend to resell the item and do not know its common value. If we take the average of every investor’s value to be an estimate of the common value, then the individual values are distributed around it in some way. The investors who “won” the auction, meaning they got the share of stock in the end, are the ones whose estimates were above the common value as we defined it. If the share price eventually settles back down to the common value or below, then the “winning” investor will lose money, demonstrating a prime example of the winner’s curse.
One recent example is the Snap Inc IPO that took place earlier this year. Shares were offered for around $17 each initially, but within a day of trading, the most optimistic investors had pushed the price up to $25. They won the auction by being able to obtain shares of the company, but in fact, they lost significantly when shares dropped steeply in price to around $15, where it remains today.
Sources:
http://fortune.com/2017/03/21/snapchat-snap-ipo-wall-street/
http://fortune.com/2017/03/02/snapchat-ipo-snap-disaster/
http://www.ipo-underpricing.com/UP/Underpricing/Modelle/GG/e_Winners%20Curse.html
https://www.ecb.europa.eu/pub/pdf/scpwps/ecbwp428.pdf?c2ec5097d1527918d87c2c5b45ebe24b
https://www.dailyreckoning.co.uk/penny-shares/tech-investors-and-the-winners-curse/
http://www.etf.com/sections/index-investor-corner/swedroe-ipos-overhyped-investment-idea?nopaging=1
Does Google give too much prominence to Wikipedia
https://econsultancy.com/blog/8987-does-google-give-too-much-prominence-to-wikipedia
Recent research has raised concerns about the overwhelming prominence of Wikipedia links consistently in the top spots of google searches. According to the research conducted by Intelligent Positioning, 96% of noun searches in google were positioned in the top five ranking spots on page one. The article discusses that it certainly makes sense for nouns to generate top ranking Wikipedia results because these tend to be informational searches. For example, searching the world “flower” positions its Wikipedia page at the second spot on google. If a search is so broad and general, in my mind it makes sense for Wikipedia to be a top result. Wikipedia gives the most basic and straightforward information on the internet, so a basic and straightforward result should be generated back. However, it is interesting that searches relating to specific brands (proper nouns) would generate such a high result for Wikipedia as well. While some people seem to think that google is intentionally favoring Wikipedia, I personally have my doubts. Wikipedia is a non-for-profit company whose mission is to empower and engage people across the world by providing information to them. Due to the fact that they have no monetary incentives driving their motivation for this encyclopedia it seems like a stretch to say that Google would purposefully be favoring them.
This article explains how PageRank can seem spit back results, due to the algorithm, that may sometime seem biased. However, Wikipedia is ranked so highly because it is linked in so many other pages. As seen in class, websites that are linked in many other sites garner a higher ranking. However, it is interesting to point out that many other Wikipedia pages are linked to each other. They also include extremely specific parameters within each page. Additionally, they include well defined boundaries, which can easily be identified by keywords and links to other Wikipedia pages with related content and information. Based on my understanding of this concept from lecture and the article, it makes sense that Wikipedia would rank so highly. Before the internet, if people needed to find information, a hardcopy encyclopedia was a good place to start.
Google’s new search algorithm
There is no doubt that Google is ubiquitous in today’s age, where information can be accessed by a simple query and a click. PageRank, the innovative endorsement algorithm developed by Larry Page and Sergey Brin, shaped the way link analysis is calculated in the world wide web. Since the beginning of PageRank, Google has continuously made improvements to its search algorithm, the most recent being the Fred update. In this update, Google targets websites that “prioritize monetization over user experience” due to “aggressive advertisement placement.” The update also affected websites with poor-quality backlinks (low values of trust and citations), which are caused by broken or “unnatural” links or poor domain authority.
In class, we discuss link analysis and its applications in modern web search. Just as we learnt about assigning values to web page nodes as a way to determine the ‘value’ of a website, Google’s search algorithm not only continues to implement this algorithm, but it is also changing with how the public reacts to the quality of these websites. The latest update to its algorithm seems to focus on the “trust” of a website; the algorithm thus determines the location of a web page on its search results. Today, Google’s search algorithm is essential to many businesses, who rely on these algorithms to stay on top of search results. If these businesses fell off the top search results due to the changes in Google’s search algorithm, they could incur losses because of their loss of page hits.
The article also gives advice to site owners on how to respond to Google’s updates. It focuses heavily on the quality of the content that a website should show, even including cleaning its link profile, which are the links that direct endorse that particular website. This update enhances user experience because web developers have to take into account the sources of their links and their advertisement placements, which affect the user experience and value of the website. For businesses, this update is even more important, because of how easily link analysis and the value of their website can affect the rank of their website on search results, and thus the businesses themselves. Of course, Google will continue to update its search algorithm and cater to the audience’s response to these websites as link analysis is continuously developed.
Link: http://www.wordstream.com/blog/ws/2017/08/24/google-fred-update
This Is Why We Can’t Have Nice Things-Page Rank Edition
RIP Google PageRank score: A retrospective on how it ruined the web
One of the reasons why Google has so prominently remained the top search engine in the world over the years is a tool called “page rank”. Page rank was an added feature to the Google toolbar that provided a different rank for each page one might visit when clicking on a link via Google. Essentially, it provided users with a concrete number that estimates exactly how credible and important Google considers a web page to be. Google’s particular algorithm contributed to its success over other search engines such as Yahoo! or Bing; it really is effective. It did serve as a very useful asset for an assortment of institutions, whether it be individuals trying to conduct research, or a company trying to determine how they should advertise. The above article details the long, arduous life of the availability of page rank to the general public. While it technically did always exist as Google’s method of queueing links to display as a search result, it wasn’t always available as something users could see, until the year 2000. Unfortunately, this grand reveal to the world turned out to be much more problematic than anticipated.
As we have learned in our INFO 2040 class, one of the most popular utilizations of page rank is executed in the process of determining an advertising scheme. When trying to figure out what location is best for an advertiser to place their product, it is quite apparent that different companies may get different levels of success at varying websites. There are several factors at hand: the price of the ads, the valuation of a website by the advertiser, the number of clicks involved, the number of websites that point to (or mention) other websites, and of course, the decisive market clearing prices. Clearly, this is going to create a competition amongst websites to attempt to achieve the best page rank scores so that they can increase their self-worth. This competition led to the formation of several third-party service organizations that used dishonest tactics and fake websites to unnaturally increase a website’s page rank. This certainly ruined the entire integrity of the page rank availability, and many law suits were created over Google’s right to shut down websites that “cheated” their way into appearing credible. After over a decade of Google allowing this chaos to ensue, they have recently shut down the availability of page rank scores to the normal users. Without a score to base things off of, third party companies have zero shot at uncovering Google’s true page rank algorithm. Abuse of the system has led to the removal of a great tool for Google users everywhere. In other words, this is why we can’t have nice things.
Google and Accelerated Mobile Pages (AMP)
https://www.wired.com/2016/02/googles-amp-speeding-web-changing-works/
Over the past year or two, I’ve been seeing the structure and layout of Google search results change, specifically on mobile. Generally, I found that when searching trending news phrases, the Google results page will yield a horizontal bar of search results in the form of Google cards. Each card features a logo header from the news article’s source, an image from the article, and the article’s headline underneath the image. At the bottom of each card is Google’s lightning bolt AMP logo (short for Accelerated Mobile Pages), followed by how recently the article was published to the Internet (or perhaps, the most recent time the article was cached by Google’s AMP system). When a user clicks on one of these AMP results, they are taken to a modified version of the webpage that has been pre-rendered and pre-cached by Google so that it can be served to the user with a shortened loading time. The Wired article linked at the top of this post discusses this AMP system, and explains how it speeds up the web from a technological perspective. Connecting this to topics we covered in class, I find that there is also a human angle to this phenomenon, and that the AMP system can speed up how users react to the web.
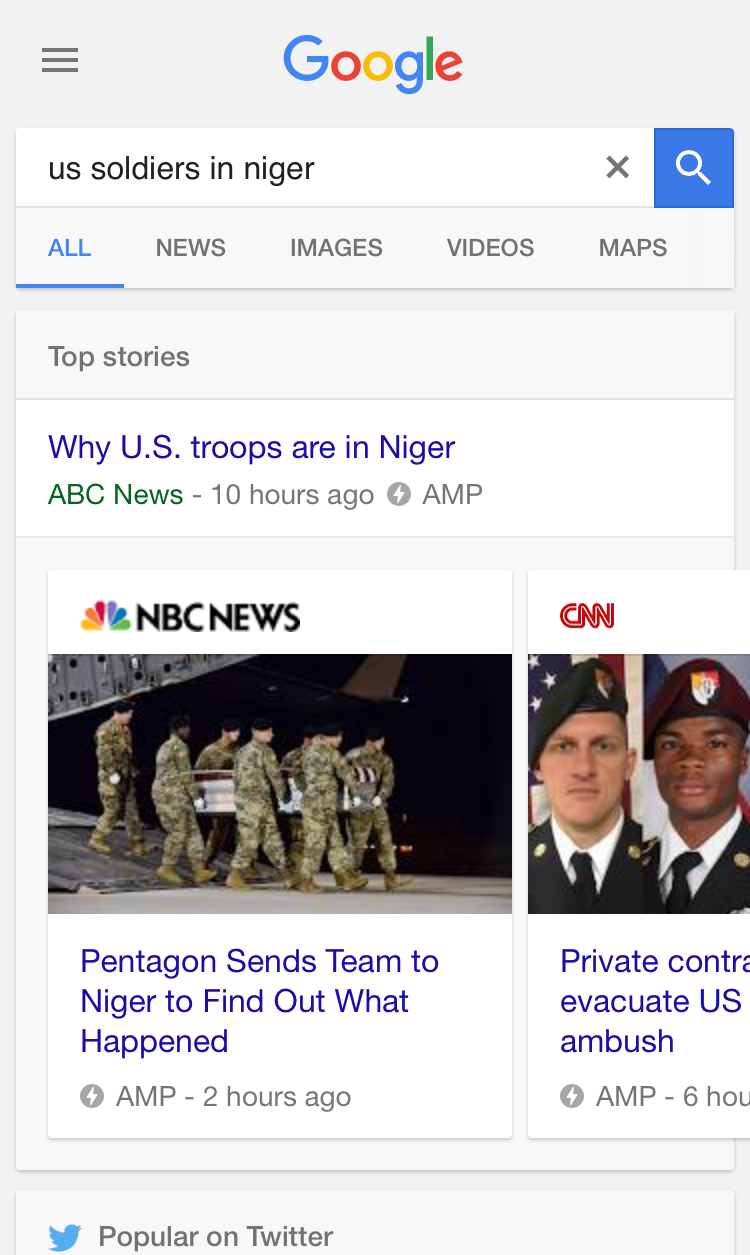
We learned in class that two web search problems that search companies have to solve for are Scarcity and Abundance. In this case, I find that Google’s AMP project can be used as a user-side solution to the Abundance problem. The Abundance problem arises when there are millions of “relevant” pages for a given search query, as there is the need to determine which are the “best” ones. Google already figured out how to collect relevant search results a long time ago, but there has always been the issue of how the results are presented to the user, such that the user can clearly see which results are the most relevant to what they are looking for, determine which result best suits their needs, and then select that result; that is to say, finding the best search results and presenting the best search results should go hand in hand for an optimal search engine. So, rather than just presenting a list of search results that only provide headline information (which, granted, are listed in order of decreasing relevance), the AMP system shows users immediate and pertinent information about relevant links: the combination of source, headline, image, and recency information gives users the most possible data by which to quickly sort through highly relevant links and select the one that best suits their search needs. This is compounded by the fact that Google’s AMP system inherently prioritizes pages with high importance based on referral counts and other link data, so ultimately the user is getting the best way to select from the most relevant results. Overall, Google’s AMP system appears to be a great way to cut down on the user-side Abundance problem that inherently comes with Google’s ability to collect huge numbers of relevant results.
The Complicated World of Search Engine Optimization

Here’s an interesting article on Search Engine Optimization (SEO) techniques:
5 SEO Strategies to Ditch in 2017
Based on the articles related to Search Engine Optimization, it seems like the practice is very important to people with websites, especially ones linked to a new or growing business. Each year, many news publications write articles advising businesses on how to optimize their websites for search engine rankings. Most of these articles claims to know the tricks to getting the best ranking. It is clear however, that the true algorithm is far more complicated than the “tips and tricks” the articles provide.
The Huffington post article recommends several things to avoid when trying to boost search engine rankings. The most interesting suggestion is ditching “Unnecessary Link Building”. The idea of including links in one’s webpage to boost rankings is directly connected to the idea of the Hub Update Rule and the general PageRank system. Traditionally, according to the article, websites would boost their Hub value by linking to arbitrary authority pages (i.e. Wikipedia). However, according to the article, it’s clear that while links still matter, search engines and ranking authority sites like RankBrain know the difference between fake links and relevant ones, and linking to a site with a high authority score doesn’t inherently help boost your site. This indicates that search engine ranking systems are far more complicated than what we’ve learned in class to date.
« go back — keep looking »