Based on user and stakeholder feedback, extracting cited references from arXiv papers and providing links to those references for readers was identified for development under the 2017 arXiv Roadmap, based on input from the arXiv user survey. We have also heard from our API consumers that access to cited references would be valuable. arXiv already detects arXiv identifiers in cited references (for LaTeX submissions), and converts those identifiers to hyperlinks to the corresponding arXiv paper in the final PDF.
Over the past several weeks we’ve undertaken an exploratory project focused on reference extraction and possible scenarios for reference linking. This post is a brief snapshot of what we’ve done so far, what we’re hearing from users, and some thoughts about where we go from here.
Extraction prototype
As part of the Classic Renewal strategy for arXiv NG, we decided that the reference extraction feature should be developed as a stand-alone service rather than tightly integrated into the existing system. For the purpose of a prototype, we also initially considered implementing the feature as a fully-automated process, but see below.
Initial work on the prototype focused on two questions:
- Can we reliably extract cited references from a wide range of arXiv papers, and what is the range of quality and completeness of those references?
- Can we reliably inject links alongside those cited references in the PDF version of a paper?
Rather than invent a reference extraction tool from scratch, we evaluated existing reference extraction tools available under open source licenses. We found several extractors that we liked:
- Content ExtRactor and MINEr (CERMINE) – https://github.com/CeON/CERMINE– Developed by the Center for Open Science. GNU GPL 3.
- RefExtract – http://pythonhosted.org/refextract/– Developed by CERN; spun off from the Invenio project. GNU GPL 2.
- GROBID – https://github.com/kermitt2/grobid– Developed by Patrice Lopez. Apache 2.0.
- ScienceParse – https://github.com/allenai/science-parse – From the Allen Institute for Artificial Intelligence. Apache 2.0.
We noticed right away that each extractor had its strengths and weaknesses, in terms of both extraction quality and resource consumption. CERMINE, RefExtract, and GROBID each excelled at different fields in the metadata. For example, RefExtract excelled at extracting DOIs. ScienceParse was not far behind in terms of quality overall, but had a much greater resource footprint than the others, often requiring 16GB + of RAM for a single process (compared to at most 2 GB, and usually much less, for each of the others).
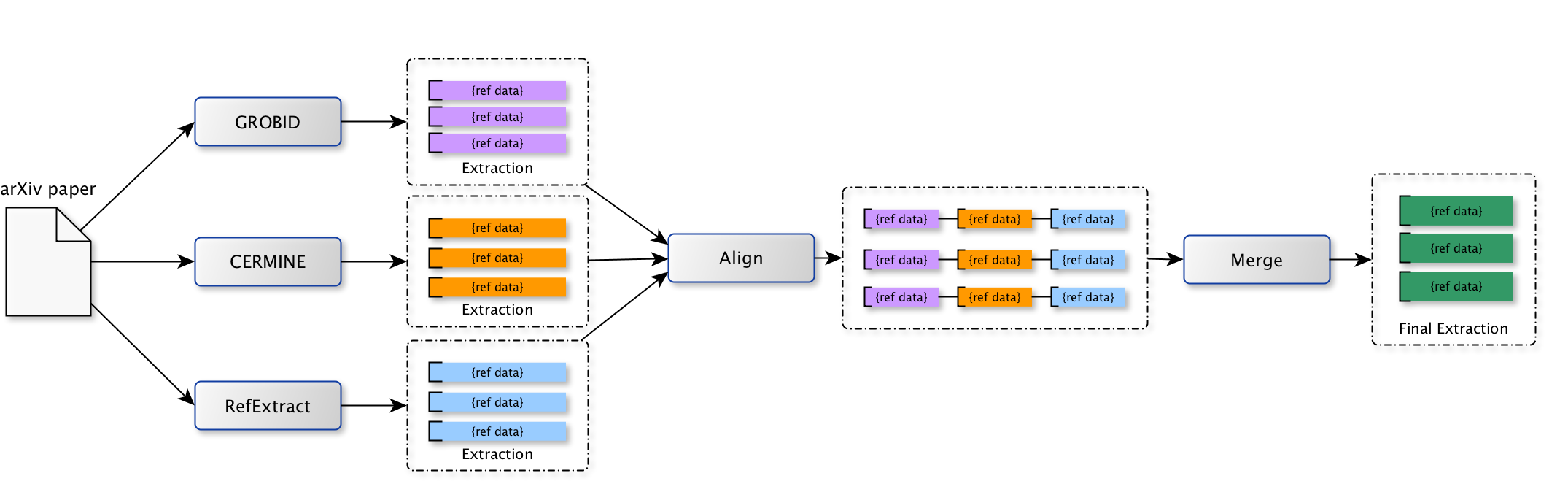
We decided to proceed with a combined approach – using CERMINE, RefExtract, and Grobid – performing parallel extractions on each paper and then combining the extracted references to produce the most reliable set of references possible. We also added a few extra extraction steps of our own to be sure that we caught arXiv identifiers, and to supplement DOI detection. We then integrate those extractions using a likelihood-based approach:
- The independent extractions are aligned based on the overall similarity of each extracted reference;
- For each extractor, we apply a set of weights that express our level of confidence in that extractor’s parsing of each field;
- We also apply a set of weights to each value of each field in each extraction, based on our expectations of what the value should look like. For example, publication years should look like a series of four integers, and titles should be more than a few characters but not hundreds of characters;
- Extractors then vote: if two extractors agree on a value for a field, we pool their weights;
- Finally, for each field in each cited reference, we select the value with the highest likelihood. As a rough estimate of extraction quality, we also score each reference based on how complete it is and the likelihood of each value that we selected, and we score each set of references (for a single paper) based on the mean reference quality and its variance.
Display & linking
Deciding how to present extracted references to readers is by far the most challenging and complex part of this project. Based on input from the arXiv user survey, we knew that reference extraction and linking was a very high priority for arXiv users. We considered two options:
- Display extracted references with links on the abstract page.
- Embed links in arXiv PDFs.
Links to what? The question of what precisely we should link to for a given reference is really important, and something we’re thinking a lot about. One of the decisions that we made early on is that, wherever the reader is ultimately directed, all of the links will point back to a resolver endpoint that we control. When the user clicks on a link, their browser briefly visits that endpoint; behind the scenes, we load the corresponding cited reference and, depending on the available metadata (e.g. arXiv ID, DOI, etc), the endpoint sends the user to an external resource. See below for more about where we could send readers, and how we could present those choices.
Each option presents its own unique benefits and difficulties. For example, presentation of cited references on the abstract page has become a fairly standard practice for bibliographic databases (they are “metadata”, after all), but some worry that displaying them apart from the text obscures important context (e.g. is the author criticizing a work, or building on it?). We also know that some users link directly to the PDF, bypassing the abstract page entirely. On the other hand, we recognize that authors take great pains to craft their papers, and that modifying the PDF version of their paper may be overly intrusive. Injecting links into PDFs raises quite a few other procedural issues: would we inject links retroactively? If so, would that entail creating a new version of every paper in arXiv? Or should we offer the link-injected PDF as a stand-alone “enhanced PDF” that is independent of the author’s authoritative version? We considered those issues, and a variety of other sticky considerations, at length.
Another important consideration for the arXiv team was the broader question of when to implement new features ourselves, as part of our core service, and when to empower other developers innovate using our content and APIs. People are already working on arXiv references! Fermat’s Library recently released a Chrome extension called Librarian, for example, that provides links to cited references while browsing arXiv PDFs. Empowering those kinds of innovative external projects adds value for users while freeing us up to focus on crucial core services.
With all of those considerations in mind, we decided to focus first on displaying references on the abstract page, and meanwhile to start tackling some of the stickier problems with manipulating PDFs. This also gave us time to finish some much-needed work on our AutoTex pipeline, which one of our developers has been diligently pursuing.
Our talented new UX developer has been hard at work on integrating the references into the abstract page in a way that respects the austere look-and-feel that we all love, and we’ve gotten excellent feedback from users as we go along. We’re looking forward to demonstrating a prototype of the new abstract page soon.
But what do users really want?
One of the really wonderful things about developing arXiv is that we have an enormous user base that is extremely engaged. When we’re not sure about how user’s feel, we can pose a question online and get hundreds of responses in the first hour. Data! After working on reference extraction and display for a little while, we started to get some pretty strong feedback about some of our choices. This was a great opportunity for us to set aside our assumptions about what users really wanted, and get some data. So we did!
Want to participate in future user surveys, and provide feedback to the development team? Please join our user and usability group. Thanks to the 771 of you who provided feedback on reference extraction!
Here are the questions that we asked, and the responses that we received from users (with bootstrapped 95% confidence intervals).
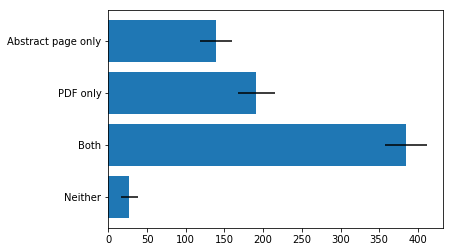
Q1: as an arXiv READER would you prefer that we:
- display linked references on the abstract page
- add links to the references section of a PDF
- both
- neither
Q2: (if answered “both” in Q1): You answered “both” to the previous question. If you had to choose just one, which would you choose?
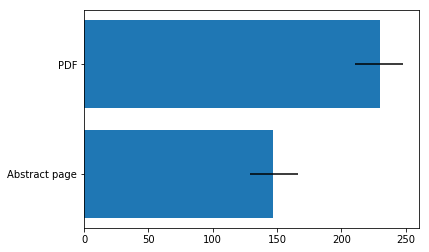
Based on the above two questions, which is more important to users: PDF links or abstract page links?
Since both Q1 and Q2 ask about injecting links into PDFs versus displaying references on the abstract page, we pooled those preferences from both questions. I.e. we combined “PDF only” from Q1 with “PDF” from Q2, and the same for abstracts. Overall, if we had to choose just one, links from PDFs are preferred to links from the abstract page.

Q3: as an arXiv READER, if we were to add links to the references section (bibliography) of a PDF, where should those links go (Recall that we already add links to arXiv articles, when possible)
- To the authoritative, published version (paper on a journal’s website, for example, if applicable)
- To search engine results (Google Scholar, for xample)
- To both the authoritative, published document AND search engine results (provided multiple links for the reader to choose from)
- Somewhere else (please specify)
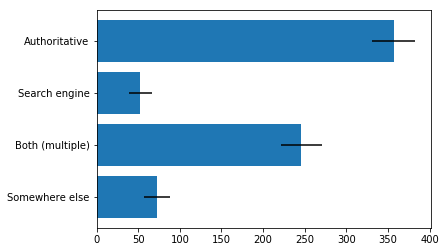
Of the 71 users who selected “somewhere else,” 26 suggested that a free/open-access version be preferred if available.
Q4: as an arXiv AUTHOR, would you object if we add links to the references section of the PDF version of your article?

Q5: at best, the quality of the extracted references and their corresponding links is only as good as the source document from which they are derived. Should AUTHORS be able to OPTIONALLY edit or correct those references?

Take-aways
- Given the choice, the simple majority of readers want links on both the abstract page and in the PDF. But there are also quite a few readers who prefer to see links in one place or the other.
- If we had to choose one over the other, by a simple majority readers prefer that links be in the PDF.
- Readers strongly prefer that links point to an authoritative source (e.g. journal), and there is also substantial support for providing links to both an authoritative source and to search results (e.g. Google Scholar). In the freeform comments at the end of the survey, quite a few people voiced concern about the idea of linking to commercial platforms, especially if the links were in the PDF. Several users pointed out that tools like OADOI make it easier to find open access options.
- The overwhelming majority of authors responding would not object to injection of links in their PDFs. Despite the quantitative “no”, when we look at freetext comments we see a number of heartfelt pleas not to mess with arXiv PDFs, from both the author and the reader’s perspective. For example, “Please don’t insert anything in the authors’ PDFs! This should be absolutely up to the authors.” and “Please, please, please DO NOT MESS WITH THE PDFs!”. It’s clear to us that, if we do provide links in PDFs, we need to be extremely careful to respect the wishes of authors at all times. We hear you!
- The overwhelming majority of authors responding prefer that the references be editable or configurable in some way. It’s pretty clear from this result that reference extraction should be connected to the submission process. For example, especially if we were to offer reference links injected into PDFs, this would absolutely need to be opt-in and provide appropriate previews. It also means that displaying references for papers retroactively is not a good idea, although we could offer the option to display references on the abstract page for previously-published papers at the author’s discretion.
- Several users suggested variations on: “Why not have this feature as some kind of latex package, or PDF preprocessing stage? Then the website only checks if references have links, as one ‘strongly recommended feature for uploaded PDFs’; but the authors [have] full control of PDF available online.” Something along those lines seems promising to us, too.
Where we are now
Our protoype of the reference extraction pipeline itself is in good shape, and we’re polishing it up for production. Knowing that reference extraction and linking needs to take place at or around submission time helps to inform how the services that provide that functionality should integrate with the rest of the system. That has helped us to refine the architecture (described below), and we’re making finishing touches on implementing the parts of the system that do the work of extracting, storing, and making available the extracted metadata.
We’re also pushing ahead with making references available on the abstract page, and we have gotten some excellent feedback (in a separate survey; thanks all!) about how to do that right. One thing that we’re considering right now is how to give readers control over where the links for those references take them, and we’ll have more to say about that shortly.
Now with a freshly-polished AutoTeX pipeline, we’ll take another look at whether we can provide link-injection for PDFs as an optional, configurable, unobtrusive service for authors. In the meantime, we encourage readers to give Librarian a try!
Architectural overview
As part of the Classic Renewal process for arXiv, we’re incrementally moving toward a services-oriented architecture. Some of what you see in the diagram have already been implemented, and other parts are still being implemented.
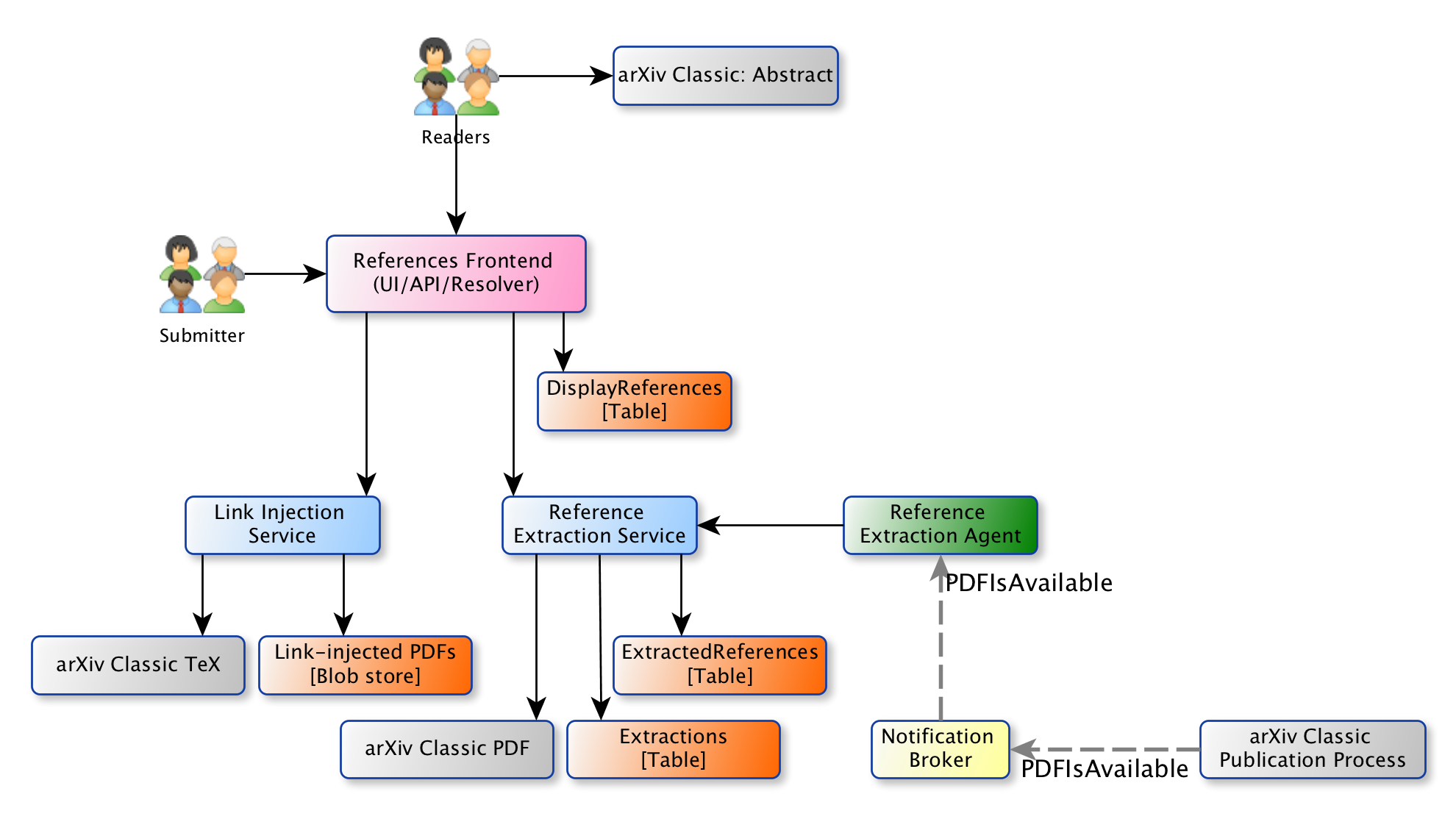
There are two backend services that do most of the work: the reference extraction service is responsible for extracting references from arXiv papers (the workflow that described earlier), and an experimental link injection service (in progress) is responsible for inserting links into the reference section in the LaTeX source and rendering a PDF.
There are two ways that reference extraction can be initiated. One pattern that we’ve considered is performing extraction automatically when a new PDF is available. In that scenario, the publication process produces a notification about the PDF, which is relayed to an “agent” by a notification broker. The agent then makes a POST request to the reference extraction service, which kicks off the extraction process. A second approach, which is more amenable to author involvement, is to perform extraction on demand at or around submission time: the frontend service provides a user interface for authors, and calls the reference extraction service at the appropriate point in the submission process. For example, if the user opts in, they might click a button to start reference extraction; when reference extraction completes the reference metadata are displayed to the author, who can make choices about how to proceed (e.g. choose to have links injected in the PDF). If the author approves and/or updates the references, they are stored in a separate table and treated as the authoritative version of the reference metadata. For display on the abstract page, references are available via a RESTful API.
The frontend service provides a link resolution endpoint. If we were to inject links into PDFs, this is where those links would point: the link would include the arXiv ID of the current paper, and a unique identifier for the specific reference. In the recent prototype, when a user lands on that endpoint the service loads the cited reference and, depending on the data available for that reference, redirects the user to the best available source (e.g. if an arXiv ID is available, to the abstract page of the cited arXiv paper). To give users more choice over where they are redirected, we might present an intermediate page that provides several options (e.g. authoritative version via DOI, open access version via DOI, etc).
Next steps
Users who responded to our surveys have provided excellent guidance and insights about how to implement reference extraction and linking in a useful and thoughtful way. We have a lot to think about! Our development team is poring over the excellent feedback that we’ve received so far. Look for updates in the coming weeks.