by Brett Haranin
Introduction
At RAIS, Jenkins has become integral to our development workflow. Developers use it throughout the day to view the output of CI build/test jobs and to deploy application changes. The basic Jenkins user management tools worked great when only one or two developers were using it, however, as we grow our team and usage of Jenkins, we wondered if there might be a way to integrate with Cornell central authentication. We’re happy to report that there is a SAML plugin for Jenkins that works well with the Cornell Shibboleth service.
This post will focus on the “how” of setting up Shibboleth with Jenkins. For a deeper look at Shibboleth and how it works, see Shawn’s post here: https://blogs.cornell.edu/cloudification/2016/07/11/using-cornell-shibboleth-for-authentication-in-your-custom-application
Getting Started – Basic Test IdP Setup
Add and configure plugin
The first step is to install the Jenkins SAML plugin under Manage Jenkins -> Manage Plugins. The plugin information page is available here: https://wiki.jenkins-ci.org/display/JENKINS/SAML+Plugin. Note, v0.6 or higher is required for compatibility with Cornell Shibboleth.

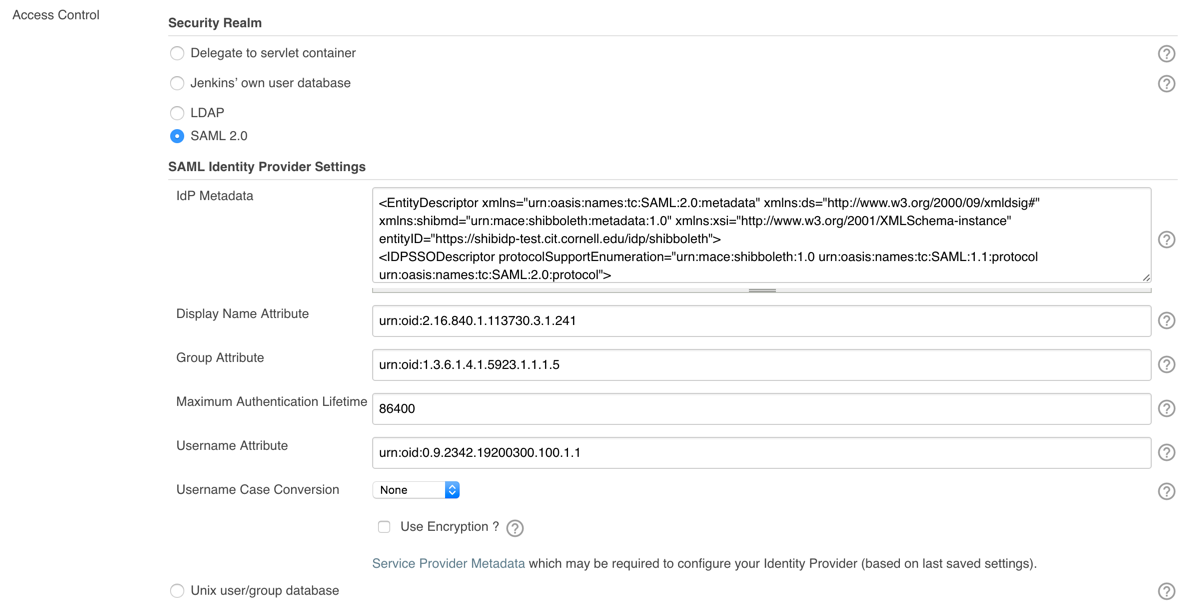
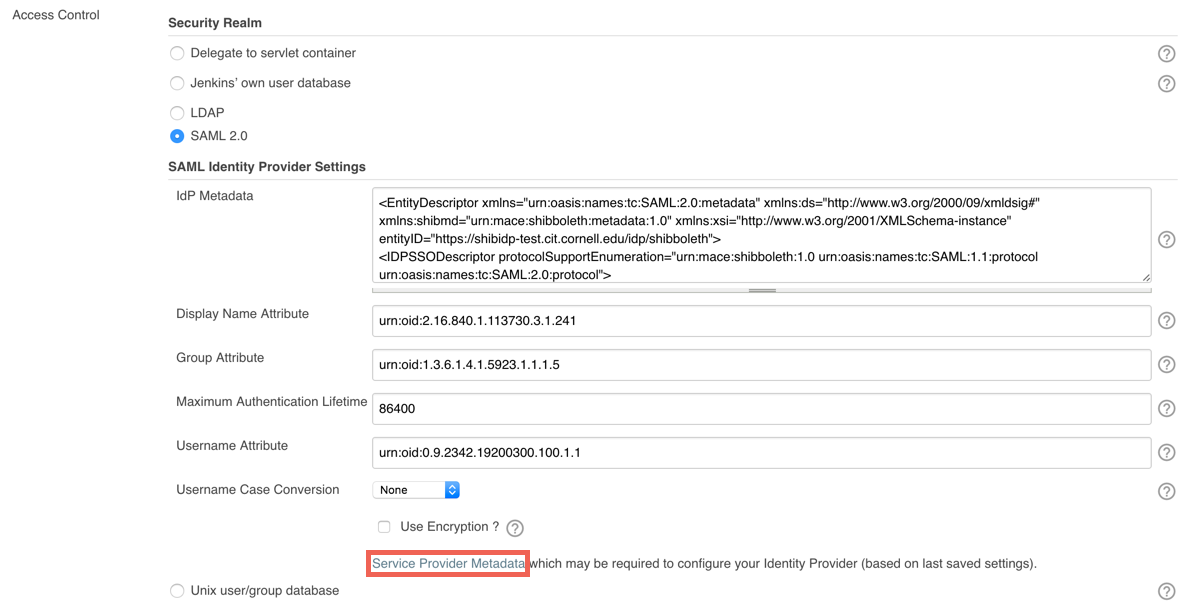
Next, let’s configure the plugin. Go to Manage Jenkins -> Configure Global Security. Scroll to “Access Control” as shown here:

For this step, the IdP metadata field should be filled with the Cornell IdP test metadata available here: https://shibidp-test.cit.cornell.edu/idp/shibboleth. Just copy it and paste it in the text box.
Fill in the Cornell Shibboleth attributes that best map to the Display Name, Group and Username attributes — the attributes we used are:
displayName: urn:oid:2.16.840.1.113730.3.1.241
edupersonprimaryaffiliation (for group): urn:oid:1.3.6.1.4.1.5923.1.1.1.5
uid (netid): urn:oid:0.9.2342.19200300.100.1.1
Finally, if you are using matrix/project based authorization (we recommend it!) ensure that usernames are lowercase netids. Also, make sure that you have at least one user (presumably yours, if you are doing administration) with administrative rights to Jenkins. After saving these settings, you will no longer be able to login with Jenkins usernames/passwords.
Save and Test
To save these settings, click “Apply”. Then, navigate to your Jenkins instance in a fresh browser (perhaps Incognito/Private Browsing). You should be redirected to a CUWebAuth screen for the test shibboleth instance.

After logging in, you should be redirected back to Jenkins and your session should be mapped to the user in Jenkins that matches your netid. There are some notable limitations to the Shibboleth test system: newer employees (hired in the last several months) will not yet be synced to the TEST directory (i.e., they won’t be able to login), and the login screen will show “TEST INSTANCE” as pictured above. In the next section, we’ll move to the PROD system for full functionality.
Next Steps – Move to Production IdP
Now that you’ve implemented and tested against the TEST instance of Shibboleth, the next step is to register your application with Cornell Identity Management so that you can use the PROD login systems.
Generate Metadata
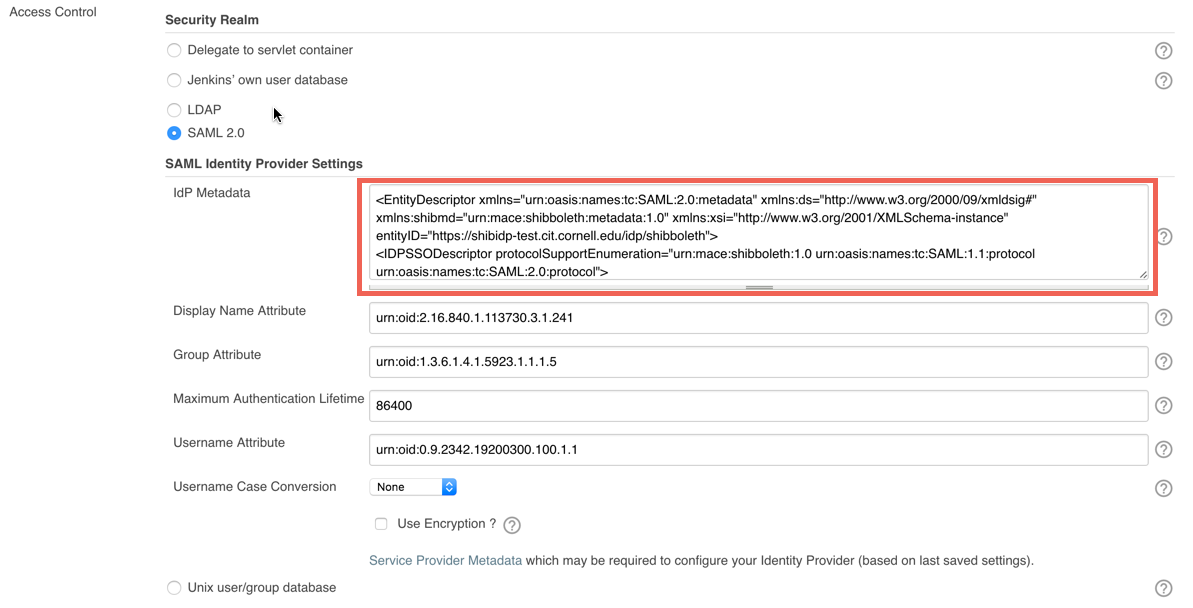
First, you’ll need to output the metadata for your Jenkins SAML service provider. To do that, go back to Manage Jenkins -> Configure Global Security. Then click “Service Provider Metadata” (highlighted below).

This will output a block of XML that looks like this, which is the metadata for your Jenkins SAML service provider:
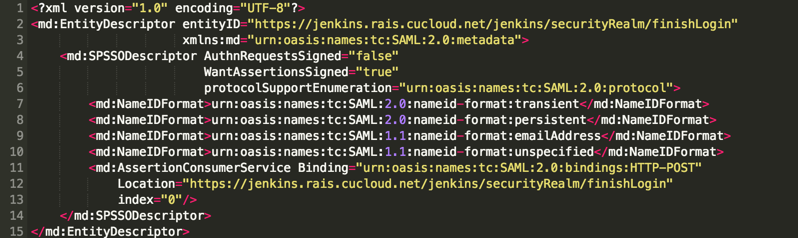
Register metadata with Cornell Identity Management
Next, we need to register this metadata with Identity Management (IDM).
Go to: https://shibrequest.cit.cornell.edu/
Fill out the initial page of contact information and choose the scope of netid roles (Staff, Faculty, etc) that should be allowed to use the tool. Note – ultimately Jenkins will authorize users based on their netid — the settings here are simply another gate to prevent folks that aren’t in specified roles or groups from logging in at all (i.e., their assertion will never even be sent to Jenkins). You can safely leave this blank if you don’t have specific restrictions you want to apply at the CUWebAuth level.
On the second page, specify that the metadata has not been published to InCommon, then paste your metadata into the provided box:

Click Next and submit your request. Submitting the request will open a ticket with Identity Management and you should receive confirmation of this via email. Once your application is fully registered with Cornell Shibboleth, you will receive confirmation from IDM staff (normally a quick process ~1 day).
Tell Jenkins to use PROD IdP
Finally, once you receive confirmation from IDM that your application is registered, you’ll need to update Jenkins to use the production IDP metadata.
Go here to get the PROD Shibboleth metadata: https://shibidp.cit.cornell.edu/idp/shibboleth
Then, in Jenkins, return to Manage Jenkins -> Configure Global Security. Paste the metadata in the IdP metadata block (everything else can stay the same):

Save, then test that you are able to login. This time you should see the regular CUWebAuth screen, rather than the “TEST INSTANCE” version.
Advanced Setup Options/Notes
- It is possible to configure your endpoint metadata to request additional attributes from the Cornell directory. If you would like to map a different value for group and then use Jenkins group permissions, you can work with IDM to get the desired attribute included in SAML assertions sent to your Jenkins endpoint, then specify those attributes on the Configure Global Security screen.
- The underlying SAML library can be very sensitive (with good reason) about any mismatch between the stated URL in a user’s browser, and the URL that the webserver believes it is running at. For example, if you terminate SSL at an ELB, a user may be visiting https://yourjenkins/jenkins/, but the webserver will be listening on port 80 and using the http scheme (i.e., http://yourjenkins/jenkins/). This manifests with an error like “SAML message intended destination endpoint did not match recipient endpoint”. Generally, the fix for this is to tell the Tomcat connector that it is being proxied (proxyPort and scheme attributes). More here: http://beckje01.com/blog/2013/02/03/saml-matching-endpoints-with-tomcat/
That’s It
Now your team should be able to login to Jenkins with their Cornell NetID and Password. Additionally, if using DUO, access will be two-factor, which is a great improvement.
For more information about Cornell Shibboleth, see the Confluence page here: https://confluence.cornell.edu/display/SHIBBOLETH/Shibboleth+at+Cornell+Page


















{kind=link}