
by Shawn Bower
Update 2019-11-06: We now recommend using awscli-login to obtaining temporary AWS credentials via SAML. See our wiki page Access Keys for AWS CLI Using Cornell Two-Step Login (Shibboleth)
This post is heavily based on “How to Implement Federated API and CLI Access Using SAML 2.0 and AD FS” by Quint Van Derman, I have used his blueprint to create a solution that works using Shibboleth at Cornell.
TL;DR
You can use Cornell Shibboleth login for both API and CLI access to AWS. I built docker images that will be maintained by the Cloud Services team that can be used for this and it is as simple as running the following command:
docker run -it --rm -v ~/.aws:/root/.aws dtr.cucloud.net/cs/samlapi
After this command has been run it will prompt you for your netid and password. This will be used to login you into Cornell Shibboleth. You will get a push from DUO. Once you have confirmed the DUO notification, you will be prompted to select the role you wish to use for login, if you have only one role it will choose that automatically. The credentials will be placed in the default credential file (~/.aws/credentials) and can be used as follows:
aws --profile saml s3 ls
NOTE: In order for the script to work you must have at least two roles, we can add you to a empty second role if need be. Please contact cloud-support@cornell.edu if you need to be added to a role.
If there are any problems please open an issue here.
Digging Deeper
All Cornell AWS accounts that are setup by the Cloud Services team are setup to use Shibboleth for login to the AWS console. This same integration can be used for API and CLI access allowing folks to leverage AD groups and aws roles for users. Another advantage is this eliminates the need to monitor and rotate IAM access keys as the credentials provided through SAML will expire after one hour. It is worth noting the non human user ID will still have to be created for automating tasks where it is not possible to use ec2 instance roles.
When logging into the AWS management console the federation process looks like
- A user goes to the URL for the Cornell Shibboleth IDP
- That user is authenticated against Cornell AD
- The IDP returns a SAML assertion which includes your roles
- The data is posted to AWS which matches roles in the SAML assertion to IAM roles
- AWS Security Token Services (STS) issues a temporary security credentials
- A redirect is sent to the browser
- The user is now in the AWS management console
In order to automate this process we will need to be able to interact with the Shibboleth endpoint as a browser would. I decided to use Ruby for my implementation and typically I would use a lightweight framework like ruby mechanize to interact with webpages. Unfortunately the DUO integration is done in an iframe using javascript, this makes things gross as it means we need a full browser. I decided to use selenium web driver to do the heavy lifting. I was able to script the login to Shibboleth as well as hitting the button for a DUO push notification:

In development I was able to run this on mac just fine but I also realize it can be onerous to install the dependencies needed to run selenium web driver. In order to make the distribution simple I decided to create a docker images that would have everything installed and could just be run. This meant I needed a way to run selenium web driver and firefox inside a container. To do this I used Xvfb to create a virtual frame buffer allowing firefox to run with out a graphics card. As this may be useful to other projects I made this a separate image that you can find here. Now I could create a Dockerfile with the dependencies necessary to run the login script:
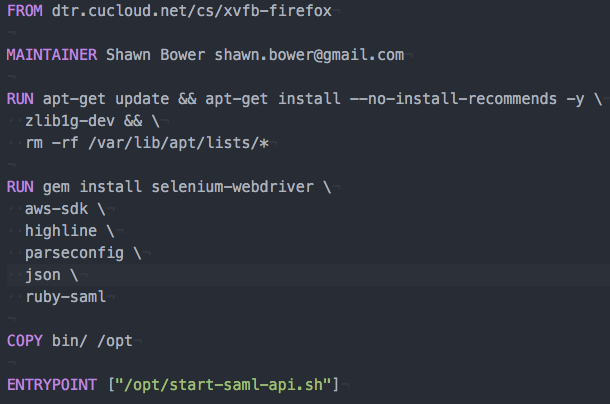
The helper script starts Xvfb and set the correct environment variable and then launches the main ruby script. With these pieces I was able to get the SAML assertion from Shibboleth and the rest of the script mirrors what Quint Van Derman had done. It parses the assertion looking for all the role attributes. Then it presents the list of roles to the user where they can select which role they wish to assume. Once the selection is done a call is made to the Simple Token Service (STS) to get the temporary credentials and then the credentials are stored in the default AWS credentials file.
Conclusion
Now you can manage your CLI and API access the same way you manage your console access. The code is available and is open source so please feel free to contribute, https://github.com/CU-CloudCollab/samlapi. Note I have not tested this on Windows but it should work if you change the volume mount to the default credential file on Windows. I can see the possibility to do future enhancements such as adding the ability to filter the role list before display it, so keep tuned for updates. As always if you have any questions with this or any other Cloud topics please email cloud-support@cornell.edu.