
by Shawn Bower
As we at Cornell move more of our workloads to the cloud an important step in this process is to run load test against our on premise infrastructure and the proposed AWS infrastructure. There are many tools that can aide in load testing one which we use frequently is called Neustar. This product is based on selenium and allows up to spin up a bunch automated browser users. It occurred to me that a similar solution could be developed using docker and Docker Datacenter.
To get started I took a look at the docker containers provided by Selenium, I love companies that ship their product in Containers! I was able to get a quick test environment up and running locally. I decided to use Selenium grid that provides a hub server which nodes can register with. Each node registers and lets the hub know what kind of traffic it can accept. In my case I used nodes running firefox on linux. To test the setup I created a simple ruby script using the Selenium ruby bindings to send commands to a node.
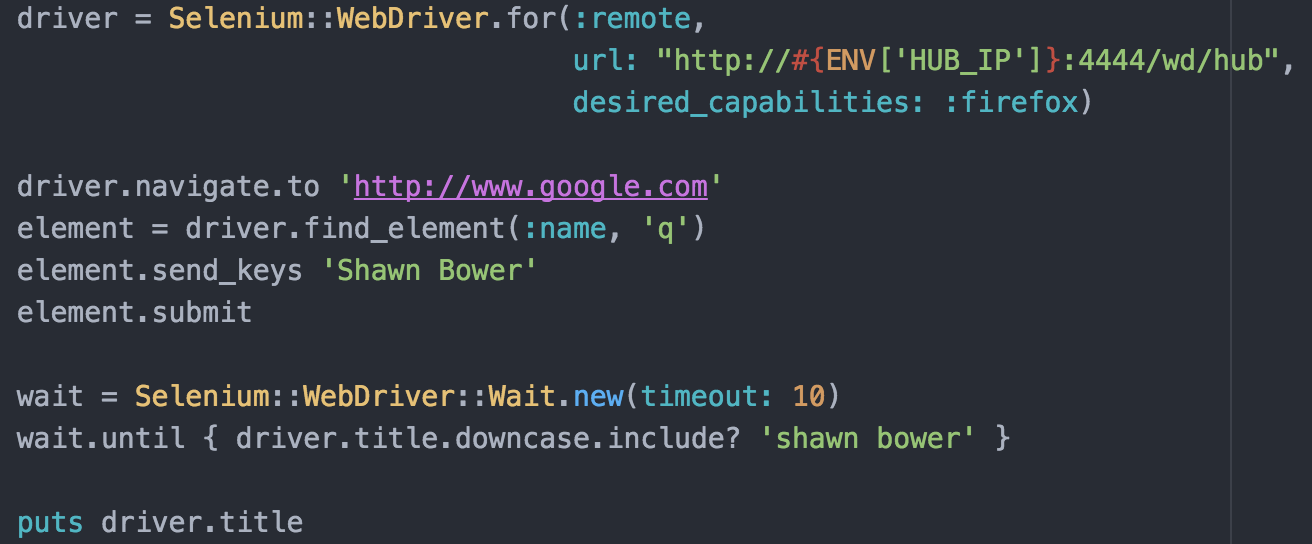
This simple test will navigate to google and search for my name then wait for the window title to include my name. While testing locally I was able to get the hub and node up and running with the following commands:
docker run -d -p 4444:4444 --name selenium-hub selenium/hub:2.53.0 docker run --rm --name=fx --link selenium-hub:hub selenium/node-firefox:2.53.0
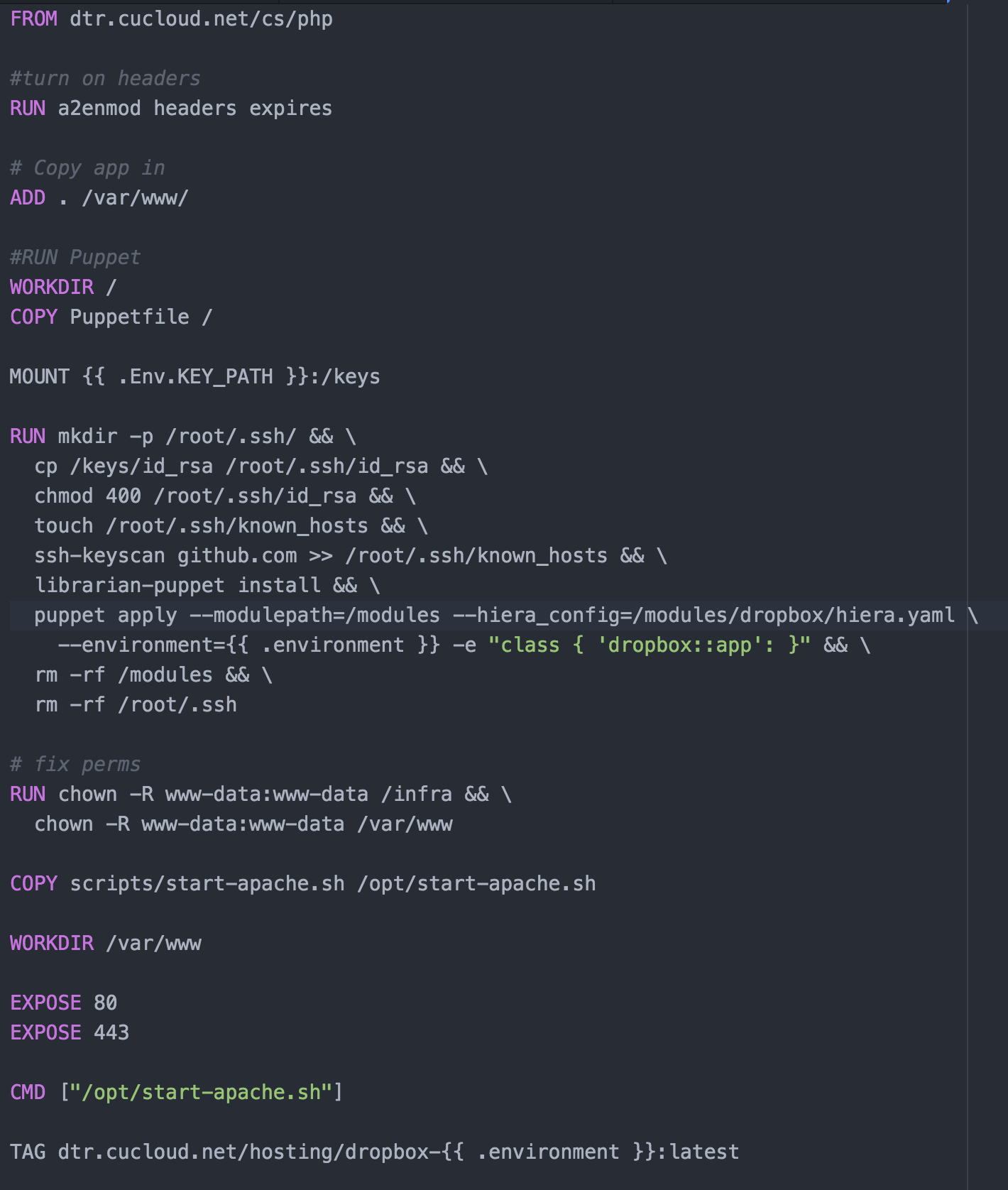
I was then able to run my script (exporting HUB_IP=localhost) and life is good. This approach could be great for integration tests in your application but in my case I wanted to be able to throw a bunch of load at an application. Since we have some large Docker Datacenter clusters it seemed to make sense to use that spare capacity to generate load. In order to deploy the grid/hub to our cluster I created a docker-compose.yaml file.
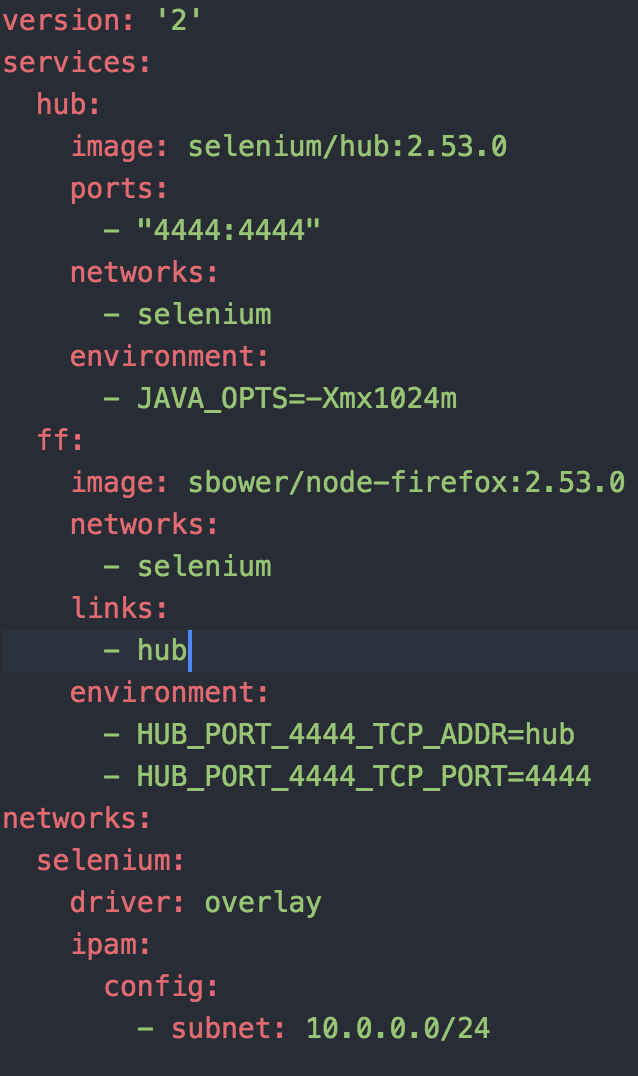
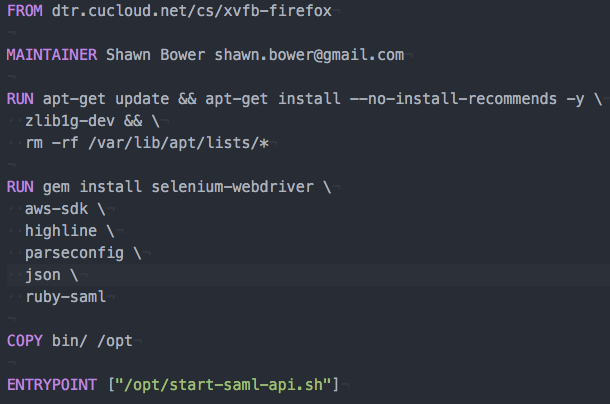
One thing to note is that I’m using a customized version of the node container, I will come back to this later. Now I am able to bring up the grid and node as such:

I can now use the docker-compose ps command to find out where my hub is running.

Now I’m ready to launch my test. Since all the things must run inside containers I created a simple Dockerfile to encapsulate my test script.
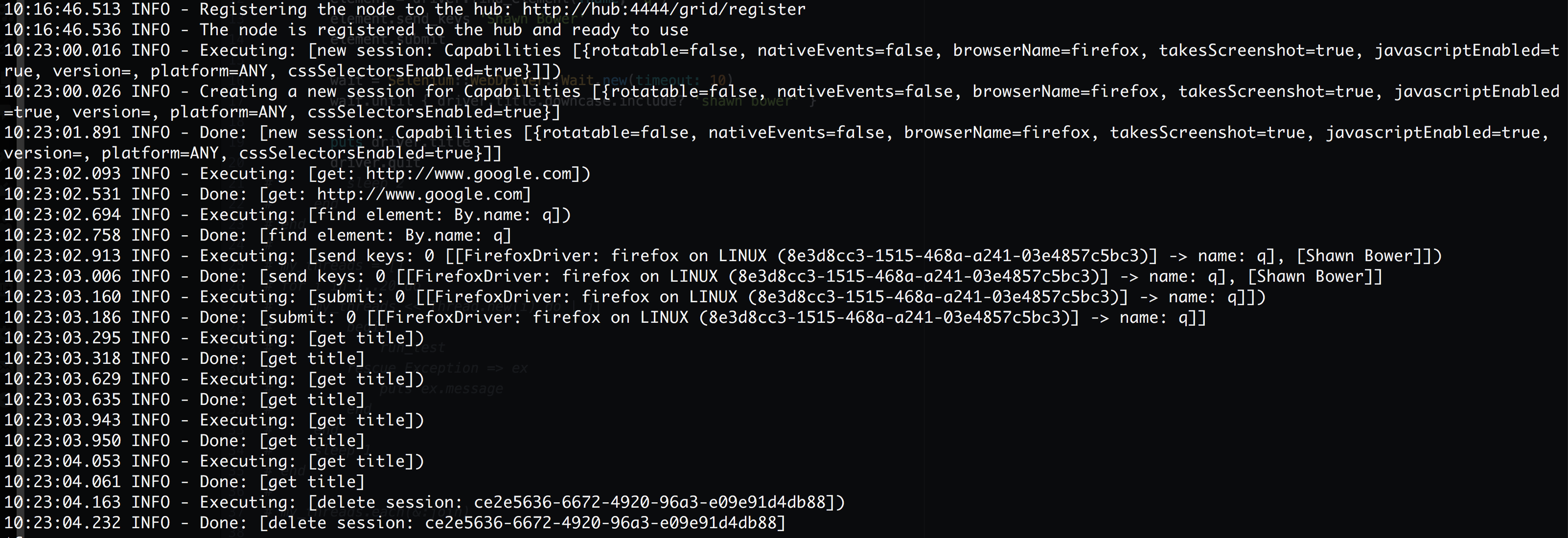
Then I can kick off the test and when it finishes I want to grab the logs from the firefox node.
docker build -t st .
docker run -e “HUB_IP=10.92.77.33” st .
docker logs ldtest_ff_1
We can see the how Selenium processes the script on firefox. Note that “get title” is executed multiple times. This is because of the waiter that is looking for my name to show up in the page title. Sweet! Now that we have it up and running we can scale out the firefox nodes, this is super easy using Docker Datacenter!

Now we can ramp up our load! I took the script above and ran it on a loop with a small sleep at the end then spun up 20 threads to run that script. In order to get everything working in Docker Datacenter I did have to modify the node startup script to register using the IP for the container on the overlay network. It turns out this is a simple modification by adding an environment variable for the IP
export IP=`hostname -I | perl -lne ‘print $1 if /(10.\d.\d.\d+)/’`
Then when the node is launched you need to add “-host $IP”
When are finished we can quickly bring everything down.
Conclusion
It is relatively simple to setup a load driver using Docker Datacenter. The code used for this example can be found here: https://github.com/sbower/docker-selenium-load-test. This is super bare bones. Some neat ideas for extensions would be, to add a mechanism to ramp the load, a mechanism to create a load profile comprised of multiple scripts, and a mechanism to store response time data. Some useful links for using selenium with ruby and Docker.
- https://github.com/SeleniumHQ/selenium/wiki/Ruby-Bindings
- https://github.com/SeleniumHQ/docker-selenium
- https://gist.github.com/kenrett/7553278
























{kind=link}