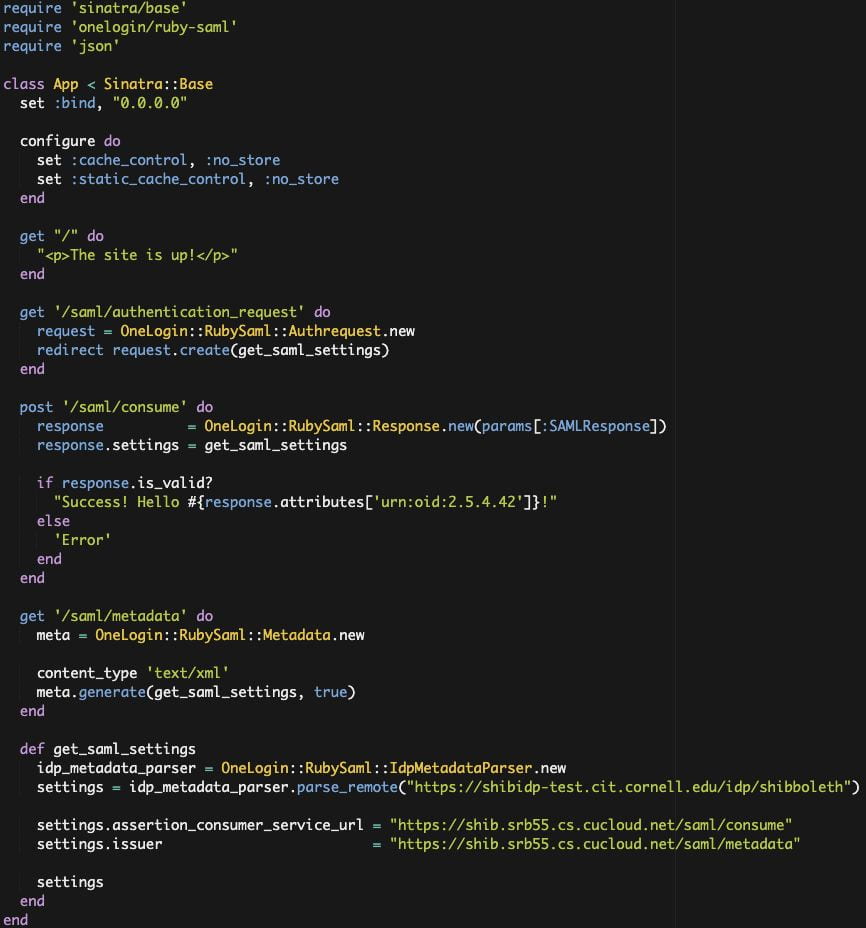
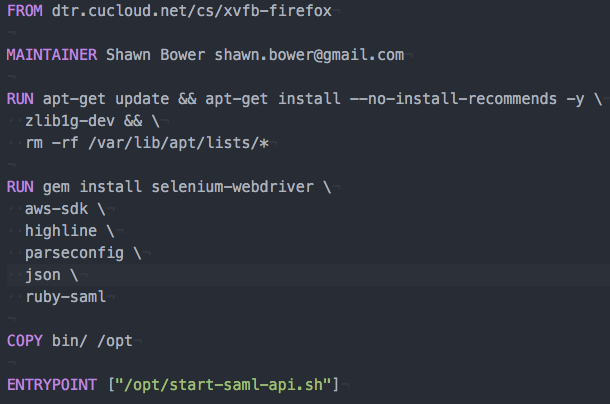
by Shawn Bower
On many of our Cloudification projects we use a combination of Docker and Puppet to achieve Infrastructure as code. We use a Dockerfile to create the infrastructure; all the packages required to run the application along with the application code itself. We run puppet inside the container to put down environment specific configuration. We also use a tool called Rocker that adds some handy directives for use in our Docker file. Most importantly Rocker adds a directive called MOUNT which is used to share volumes between builds. This allows us to mount local disk space which is ideal for secrets which we do not want copied into the Docker image. Rocker has to be cool so they us a default filename of Rockerfile. Let’s take a look at a Rockerfile for one of our PHP applications, dropbox:
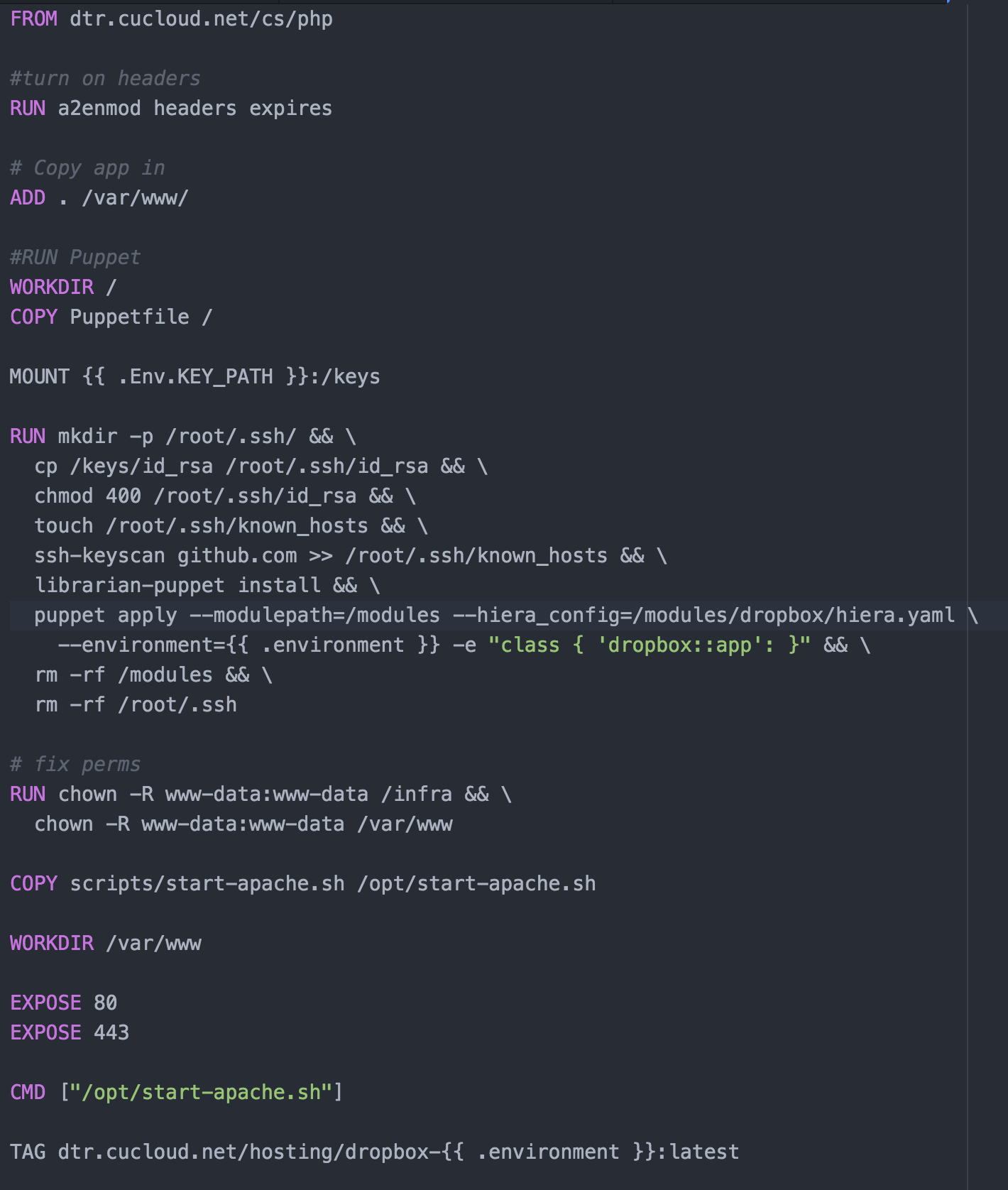
This image starts from our standard PHP image which is kept up to date a patched weekly by the Cloud Services team. From there we enable a couple of Apache modules that are needed by this application. Then the application is copied into the directory ‘/var/www/.’
Now we mount the a local directory that contains our ssh key and encryption keys. After which we go into the puppet setup. For our projects we use a masterless puppet setup which relies on the librarian puppet module. The advantage is we do not need to run a puppet server and we can configure the node at the time we build the image. For librarian puppet we need to use a Puppetfile, for this project is looks like this:

The Puppetfile list all the modules that use wish puppet to have access to and the git path to those modules. In our case we have a single module for the dropbox application. Since the dropbox module is stored in a private github repository we will use ssh key we mounted earlier to access it. In order to do this we will need to add github to our known host file. Running the command ‘librarian-puppet install’ will read the Puppetfile and install the module into /modules. We can then use puppet to apply the module to our image. We can control the environment specific config to install using the “–environment” flag, you can see in our Rockerfile the variable is templated out with “{{ .environment }}”. This will allow us to specify the environment at build time. After puppet is run we clean up some permissions issues then copy in our image startup script. Finally we specify the ports that should be exposed when this image is run. The build is run with a command like “rocker -var environment=development.”
It is outside the scope of this article to detail how puppet is used, you can find details on puppet here. The puppet module is laid out like this:
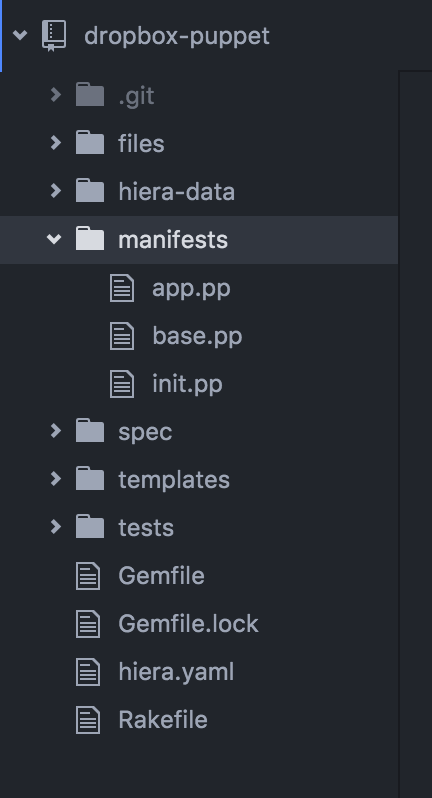
The files directory is used to store static files, hier-data is used to store our environment specific config, manifest stores the puppet manifests, spec is for spec test, templates is for storing dynamically generated files and tests is for test that are run to check for compilation errors. Under hiera-data we will find an eyaml (encrypted yaml) file for each environment. For instance let us look at the one for dev:
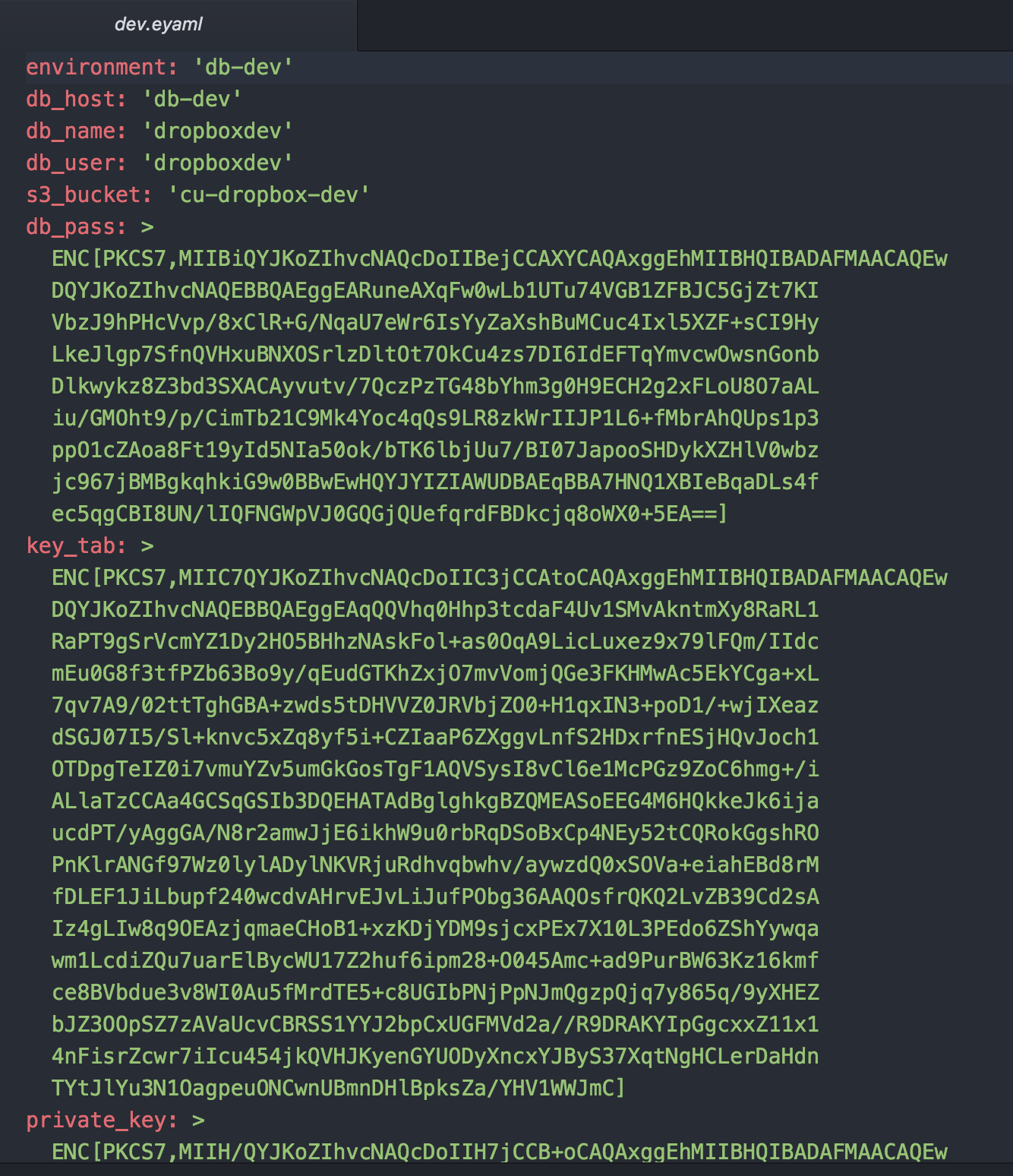
You can see that the file format is that of a typical yaml file with the exception of the fields we wish to keep secret. These are encrypted by the hiera-eyaml plugin. Early in the Rockerfile we mounted a “keys” folder wich contains the private key to decrypt these secrets when puppet runs. In order for the hiera-eyaml to work correctly we have to adjust the hiera config, we store the following in our puppet project:

The backends are the order in which to prefer files, in our case we want to give precedence to eyaml. Under the eyaml config we have to specify where the data files live as well as where to find the encryption keys. When we run the pupp apply we have to specify the path to this config file with the “–hiera_config” flag.
With this process we can use the same basic infrastructure to build out multiple environments for the dropbox application. Using the hiera-eyaml plugin we can store the secrets in our puppet repository safely in github as they are encrypted. Using Rocker we can keep our keys out of the image which limits the exposure of secrets if this image were to be compromised. Now we can either build this image on the host it will run or push it to our private repository for later distribution. Given that the images contains secrets like the database password you should give careful consideration on where the image is stored.