
by Shawn Bower
The term DevOps is thrown around so much that it is hard to pin down it’s meaning. In my mind DevOps is about culture shift in the IT industry. It is about breaking down silos, enhancing collaboration, and challenging fundamental design principles. One principal that has been turned on its head because of the DevOps revolution is the no single point of failure design principle. This principle asserts simply that no single part of a system can stop the entire system from working. For example, in the Financial system the database server is a single point of failure. If it crashes we cannot continue to serve clients in any fashion. In DevOps we accept that failure is the norm and we build our automation with that in mind. In AWS we have many tools at our disposal like auto scaling groups, elastic load balances, multi-az RDS, dynamodb, s3, etc. When architecting for the cloud keeping these tools in mind is paramount to your success.
When architecting a software system there are a lot of factors to balance. We want to make sure our software is working and performant as well as cost effective. Let’s look at a simple example of building a self healing website that requires very little infrastructure and can be done for low cost.
The first piece of infrastructure we will need is something to run our site. If its a small site we could easy run it on a t2.nano in AWS which would cost less than 5 dollars a month. We will want to launch this instance with an IAM profile with the policy AmazonEC2RoleforSSM. This will allow us to send commands to the ec2 instance. We will also want to install the SSM agent, for full details please see: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/install-ssm-agent.html. Once we have our site up, we will want to monitor its health. At Cornell you can get free access to the Pingdom monitoring tool. Using Pingdom you can monitor your sites endpoint from multiple locations around the world and get alerted if your site is unreachable. If you don’t already have a Pingdom account please send an email to cloud-support@cornell.edu. So now that we have our site running and a Pingdom account lets set up an uptime monitor.
We are doing great! We have a site, we are monitoring, and we will be alerted to any downtime. We can now take this one step further and programmatically react to Pingdom alert using their custom webhook notifier. We will have to build an endpoint for Pingdom to send the alert to. We could use Lambda and API gateway, which is a good choice for many reasons. If we want we could start even simpler by creating a simple Sinatra app in Ruby.

This is a very simple bit of code that could be expanded on. It creates an endpoint called “/webhook” which first looks for an api-key query parameter. This application should be run using SSL/TLS as it sends the key in clear text. That key is compared against and environment variable that should be set before the application is launched. This shared key is a simple mechanism for security only in place to stop the random person from hitting the endpoint. For this example it is good enough but could be vastly improved upon. Next we look at the data that Pingdom has sent, for this example we will only react to DOWN alerts. If we have an alert in the DOWN state then we will query a table in DynamDB that will tell us how to react to this alert. The schema looks like:

- check_id – This is the check id generated by Pingdom
- type – is the plugin type to use to respond to the Pingom alert. The only implemented plugin is SSM which uses Amazon’s SSM to send a command to the ec2 host.
- instance_id – This is the instance id of the ec2 machine running our website
- command – This is the command we want to send to the machine
We will use the the type from our Dynamo table to respond to the down alert. The sample code I have provided only has one type which uses Amazon’s SSM service to send commands to the running ec2 instance. The plugin code looks like:
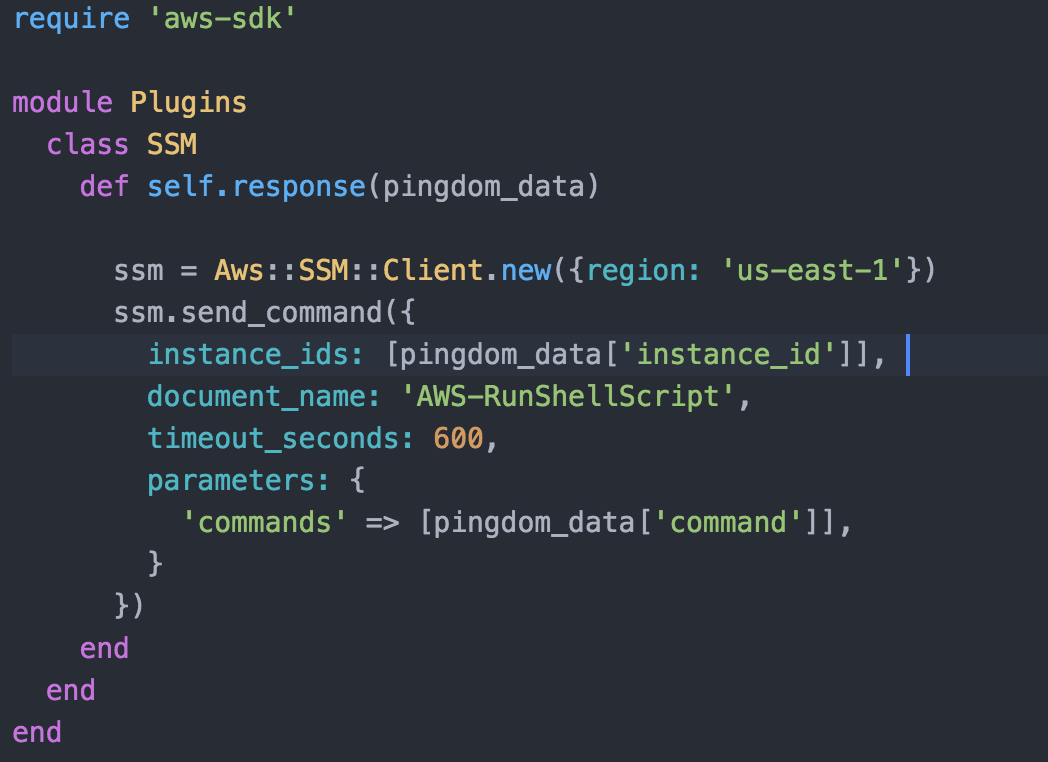
This function takes the data passed in and send the command from our Dynamo table to the instance. The full sample code can be found at https://github.com/CU-CloudCollab/pingdom-webhook. Please feel free to use and improve this code. Now that we have a simple webhook app we will need to deploy it to an instance in AWS. That instance will have to use an IAM profile that will allow it to read from our Dynamo table as well as send SSM commands. Again we can use a t2.nano so our cost at this point is approximately 10 dollars a month.
We need to make Pingdom aware of out new web hook endpoint. To do that navigate to “Integrations” and click “Add integration.”
 The next form will ask for information about your endpoint. You will have to provide the DNS name for this service. While you could just use the IP of the machine its highly encourage to use a real host name with SSL.
The next form will ask for information about your endpoint. You will have to provide the DNS name for this service. While you could just use the IP of the machine its highly encourage to use a real host name with SSL.

Once you have added the integration it can be used by any of the uptime checks. Find the check you wish to use and click the edit button
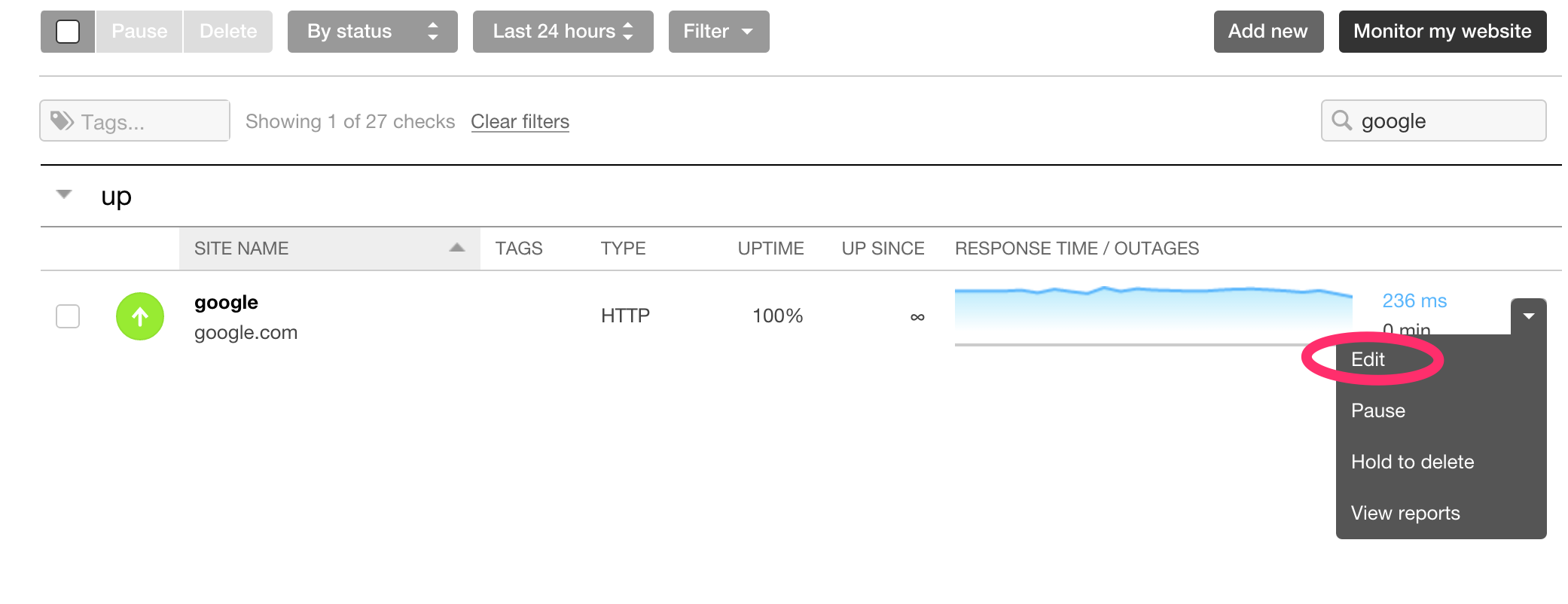
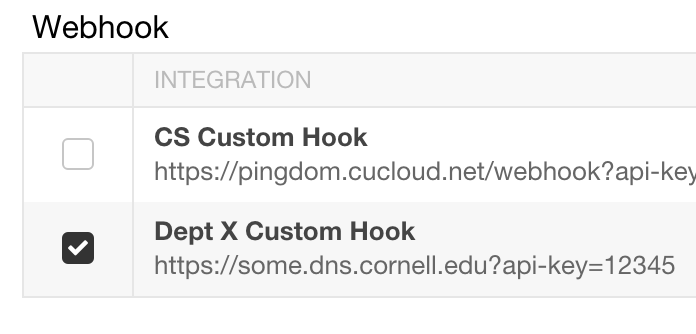
Then scroll to the bottom of the settings page and you will see a custom hooks section. Select your hook and you are all done!
This is a simple and cost effective solution to provide self-healing to web applications. We should always expect failure will occur and look for opportunities to mitigate it’s effects. DevOps is about taking a wholistic approach to your application. Looking at the infrastructure side as we did in this blog post but also looking at the application it-self. For example move to application architectures which are stateless. Most importantly automate everything!